Sparkling Water

Why Sparkling Water?
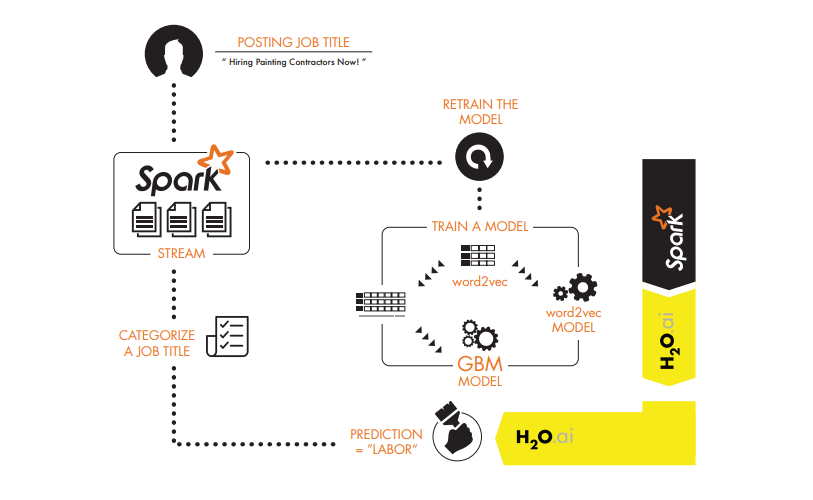
Sparling Water blends data science workflows into developers’ applications using H2O’s machine algorithms and Spark’s fast data munging capabilities
Sparkling Water enables usage of H2O algorithms with Spark Data Frames by providing a transparent API to exchange data between H2O Frames and Spark Data Frames.

Sparkling Water was designed to allow users to get the best of Apache Spark – its elegant APIs, SQL-based data munging, machine learning pipelines – along with H2O’s computation speed of fully-featured machine learning algorithms. Sparkling Water also allows for greater flexibility when it comes to finding the best algorithm for a given use case. Apache Spark’s MLib offers a library of popular algorithms directly built using Spark. Sparkling Water empowers enterprise customers to use H2O algorithms in conjunction with, or instead of, MLlib algorithms on Apache Spark.
- Parallelized data processing: H2O is designed to quickly process huge amounts of data in a distributed and fully parallelized fashion.
- Streamline model training, evaluation & comparison and scoring: H2O operationalizes this process by:
- Providing a library 01‘ ML algorithms supporting advanced, algorithm-specific features. Moreover, H2O allows combining models into ensembles (super—learners) or finding the best model with AutoML.
- Performing fast exploration of hyper-space of parameters (a.k.a. grid search).
- Providing the ability to specify various criteria that identify and select the best model, e.g. accuracy, building time, scoring time, etc.
- Ability to continue model training with modified parameters and additional relevant input data.
- Continuous modeling feedback: Visualization of various model characteristics on-the-fly during training as well as of the final model.
- Providing a library 01‘ ML algorithms supporting advanced, algorithm-specific features. Moreover, H2O allows combining models into ensembles (super—learners) or finding the best model with AutoML.
- Deployment of optimized models: Model deployment is one of the most critical elements of the machine learning process. allows for the export of trained models as an optimized code for deployment into target systems (i.e., web services, applications, etc.) The exported models can be also used as part of Spark machine learning pipelines.
- Sparkling Water deployment: Easy use of Sparkling Water with existing Spark distribution with help of published Sparkling Water package. Moreover, Sparkling Water provides two operation modes (internal and external) which reflect demand of different execution environments and allow to manage H2O cluster as part of Spark cluster or separately.
Benefits
- Seamlessly transition back and forth between Spark and H2O
- Use Scala, Python or R to build models
- Power of Spark SQL-based data munging combined with the speed of H2O
- All the features of H2O included (Flow – UI, model export)
Highlights
- Accuracy: AutoML,Ensembles,GBM,GLM,DRF,
Deep Learning
- Speed: In Memory, Distributed Computation
- Interface: R, Python, Flow
- Developers: Spark API, PySpark, Sparklyr
- Community: Expert Data Scientists, Developers, Data Engineers
- Cloud: Databricks Cloud, AWS, Azure
Features
- Seamless integration with Spark API.
- Run Scala code in Flow.
- H2O algorithms are exposed as Spark estimator enabling transparent integration with Spark machine learning pipeline
- Bringing H2O’s Visual Intelligence to MLlib algorithms.
- Support of Driverless AI MOJO pipelines