







The Making of H2O Driverless AI - Automatic Machine Learning
It is my pleasure to share with you some never before exposed nuggets and insights from the making of H2O Driverless AI, our latest automatic machine learning product on our mission to democratize AI. This has been truly a team effort, and I couldn’t be more proud of our brilliant makers who continue to relentlessly create and innovate. This blog is only a partial representation of all the hard work that has gone into this product, and I only include a selection of technical contributors here for simplicity, but the entire company has put their heart and soul into this product. H2O Driverless AI is undoubtedly an excellent showcase of the maker culture, of which we are very proud.
January 2017 – H2O.ai: data + ai + people = excellent
It all started like this, on a rainy day (pun intended) in Mountain View, California. After spending almost 5 years on creating the now industry-standard open-source machine learning platform H2O-3, some of us, the makers at H2O.ai, were ready to tackle the next obvious problem: Automatic Machine Learning with H2O Driverless AI. Especially since we had amassed the first two Kaggle grandmasters (now there are six Kaggle grandmasters at H2O.ai, out of 126 worldwide), and had participated at Kaggle for years ourselves, we knew first hand how hard it was to do more than parameter tuning and model ensembling, both of which are already done in a scalable way by H2O-3’s AutoML.
Here’s the original white board sketch by our visionary founder and CEO Sri Ambati from January 2017:

Controlled by 3 knobs in the center (accuracy, speed, interpretability), the goal of Driverless AI (then called H2O.ai) was to reduce the required user input to a minimum and allow less experienced data scientists to train and deploy the most accurate models possible, and to become an invaluable digital assistant for data scientists of all levels of expertise. It also had to be able to handle the most common types of data, make interpretable and explainable models and predictions and employ best-of-breed open-source machine learning platforms on enterprise hardware both on premise and in the cloud and had to be installable in minutes.
These were the product requirements:
- easy to use
- automatic exploratory data analysis and visualization
- best-in-class automatic machine learning for transactional, text, time-series and image data
- automatic model debugging – documentation, transparency, interpretation and explanation
- automatic pipelines for production deployment in Python/Java/C++
- easy to install on premise or on cloud
The only guidance for the development team was:
- use existing open source projects (not just those written by H2O.ai)
- if something is missing, create it and open source it
Given this fantastic challenge and ultimate creative freedom, we were ready to start coding!
We knew we needed to achieve at least the following technical milestones:
- data scientists should be able to directly contribute to the core code base
- data manipulations had to be extremely fast and efficient with memory
- we needed to avoid common pitfalls in data science such as overfitting and leakage
- we had to auto-generate large parts of the GUI, client bindings and scoring pipelines
- everything had to be parallelized across multi-core CPUs and GPU-accelerated where possible
To meet these goals, we decided to build the first version of H2O Driverless AI using a single-node design using Python as a control language for algorithms written in C++. Whatever was missing, we would create.
In contrast to H2O-3, which is written in Java using a Map/Reduce paradigm for distributed computing and massive scalability (scale out) in mind, H2O Driverless AI would use scale-up on a single box and avoid any network or communication overhead for fastest possible performance on datasets that fit onto a single node (most servers now have more than 256GB of memory, some have 2TB). At least for today, this is sufficient for a majority of use cases where automatic machine learning can add value.
Here’s a quick time line of how the different pieces came together and how we decided to design each component.
March 2017 – Python DataTable For Feature Engineering
Feature engineering is the art of re-shaping the data using domain knowledge such that machine learning models can better extract the signal from the noise. It is well known that good feature engineering can significantly improve the accuracy of many predictive models, far beyond what even the most extensive parameter tuning can do.
We knew that to master the challenging task of automatic feature engineering, we needed the fastest possible columnar data frame manipulation engine, especially for fast high-cardinality grouping and aggregating, the bread and butter for feature engineering in transactional or time-series datasets. We knew we had to use the most popular (fast, low-memory usage, flexible) open-source library available for that, data.table in R, but we had to port it to Python to fill yet another market demand.

These were the design goals for the Python version of datatable:
- multi-threaded
- big data support (including out-of-RAM)
- conservative use of memory
- efficient algorithms
- similar to R’s data.table
- open source
Python datatable version 0.7 has been released last week, and has successfully achieved all of the above design goals. It is deeply embedded in almost all aspects of Driverless AI and a key contributor to its performance.
I highly recommend watching the following two talks by my colleagues Matt Dowle, the original author of R data.table and Pasha Stetsenko, the main author of Python datatable. The data.table team (thanks to Jan Gorecki) has created very useful and always-up-to-date benchmarks comparing R data.table, Python datatable, Spark, pandas, Dask, dplyr and Julia to help the community decide which tools are best suited for many specific workloads.
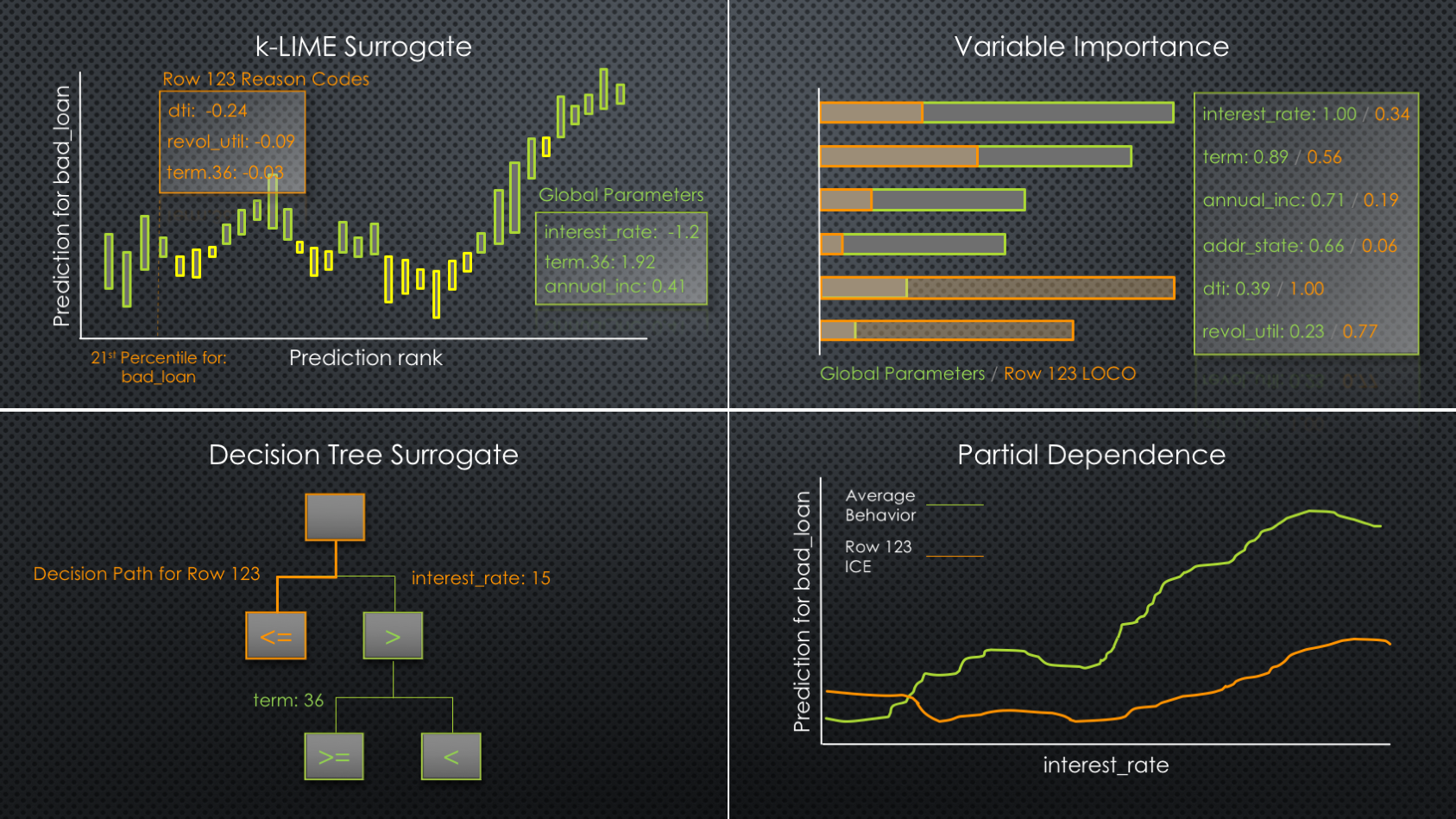
March 2017 – Interpretable Machine Learning
In the meantime, my colleague Patrick Hall assembled a team of makers and started to work on ideas on interpreting machine learning. This field was clearly ripe for innovation and needed solutions that companies could rely upon to debug models before they go to production. Every decision needed transparency and reason codes. Every what-if scenario had to be evaluated. Partial dependence plots and sophisticated surrogate models were just one way to get answers, and brainstorming and literature review was in full force. Here’s an early mock-up:
May 2017 – H2O4GPU for GPU Accelerated Machine Learning
We also needed the fastest possible machine learning algorithm implementations, especially for gradient boosting machines (GBM), the winning algorithm in the majority of Kaggle competitions on non-image problems. So we added GPU accelerated XGBoost in H2O, one of the fastest and most successful GBM implementations. It became clear that a box with multiple GPUs could greatly speed up model training, not just for Deep Learning workloads.
General relativity and supercomputing expert Jon McKinney had joined us in March and took over the efforts around
H2O4GPU for speeding up GLM, GBM, SVD and K-Means algorithms with GPUs. He quickly became one of the main committers for Driverless AI as well.
Note: Since then, the speed of Rory Mitchell’s XGBoost GPU plugin has more than doubled through tricks like integer arithmetic.
The relative speedup of our GLM solver (using a method invented by our technical adviser Prof. Boyd) on GPUs vs CPUs led us to create a demo to demonstrate the World’s fastest Machine Learning on GPUs at NVIDIA GTC conference in May 2017:

With NVIDIA’s investment in H2O.ai and their recent announcement of RAPIDS, we hope to end up with even faster GPU algorithms for statistical machine learning. We are thrilled that NVIDIA shares our vision that Enterprise Machine Learning problems require a full stack of data science solutions and statistical machine learning algorithms, and not just Deep Learning alone.
May 2017 – Evolutionary Algorithm for Feature Engineering
Kaggle grandmaster Dmitry Larko had personally created an arsenal of battle-proven Python libraries, and he blessed us with the first version of the ‘AutoDL’ recipe that automatically created optimal feature engineering pipelines using evolutionary algorithms. In every iteration of the process, features would be created based on model feedback and their predictive power would be tested by XGBoost (later also LightGBM or TensorFlow or GLM). Weak features would be discarded and the system would improve its performance continually until convergence was detected. The picture below is how it looks today, but back then, there was just a Jupyter notebook…
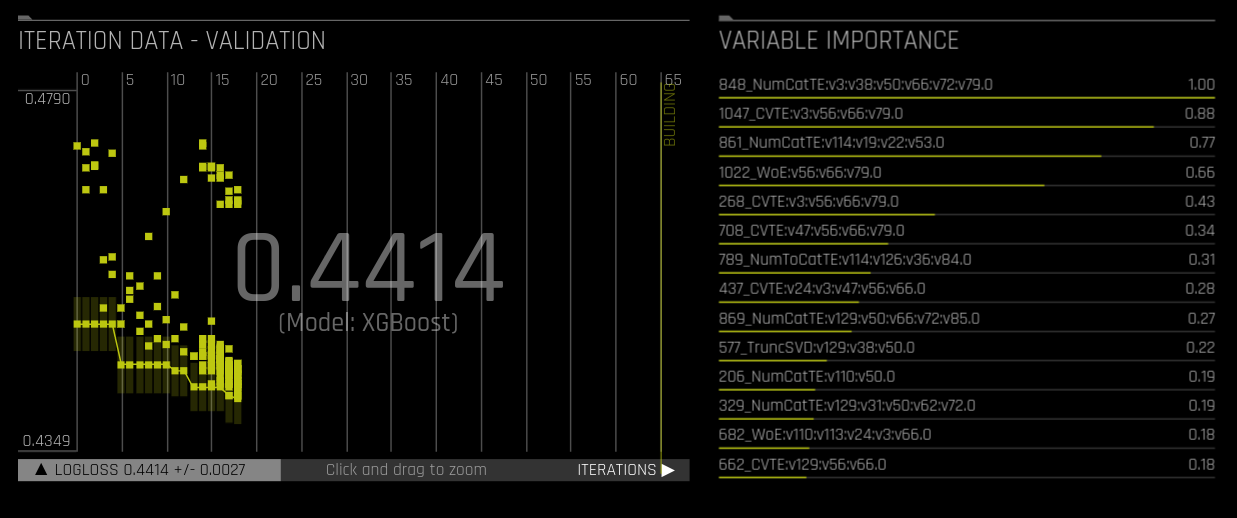
Dmitry explains some of the concepts in a webinar on feature engineering in Driverless AI, and in a recent presentation at H2O AI World.
Similar to recent advances in computers playing board games like chess or Go, our prototype of Driverless AI was now able to imitate the work of many seasoned data scientists by creating models in hours that would take experts days or weeks or even months to build. And with clever validation schemes built in (such as a modified version of reusable holdout), it was designed to avoid making the most common data science mistakes such as overfitting or introducing data leakage.
Here’s an original performance comparison of AutoDL on the Allstate Claims Severity Kaggle competition benchmark (lower is better):

May 2017 – Application Development
By May 2017, Sri’s architecture slide looked like this:
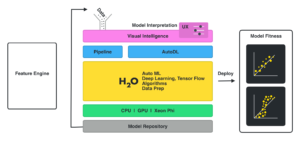
Around the same time, Prithvi Prabhu, the original author of H2O’s Flow UI, had architected and implemented the server/client application design, based on auto-generated Protobuf bindings and IPC, and he also started to work on an auto-generated UI, the state of which was populated by Python code for ease of development. In May 2017, his first prototype of the new GUI looked like this:
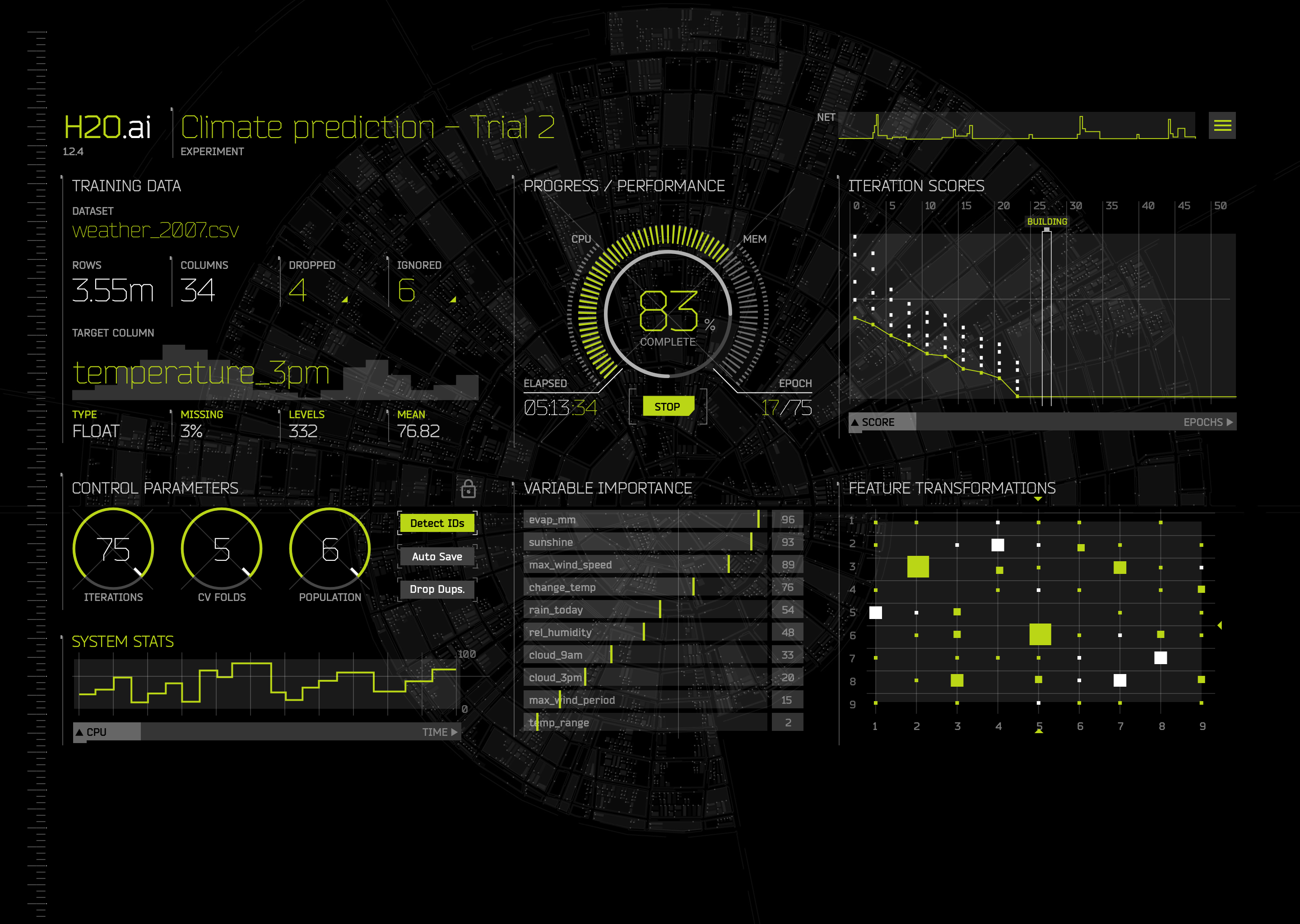
June 2017 – Automatic Visualization
By June, my colleague Leland Wilkinson had coded up another package for automatic visualization, AutoVis. He’s the original author of the statistical software package SYSTAT and the book The Grammar of Graphics, the foundation for R’s ggplot2, Python’s Bokeh and companies like Tableau.
AutoVis automatically displays only interesting (or worrisome) things about any given dataset, such as outliers or skewed histograms. One of the core components of AutoVis is scagnostics, and to make it scalable, we used Leland’s Aggregator algorithm, a kind of clustering into representative samples (exemplars) that aims to preserve outliers in the data. We initially used the aggregator as implemented in H2O-3, and as of version 1.4 we rely on an even faster version that is now part of the Python datatable (thanks to my former and current colleague Oleksiy Kononenko).
Make sure to watch Leland’s presentation of AutoVis in H2O Driverless AI for more details.

September 2017 – Final Assembly and Testing
We spent the summer integrating all the components into a user-friendly application. Armed with many years of experience in writing industry-leading robust machine learning systems, we added performance-critical improvements such as parallelization, model ensembling and additional parameter tuning methods for even higher speed and accuracy.
We wrote hundreds of tests (now in the thousands) and the complete test suite would take several hours to run on our Jenkins cluster. The product now had become a single Dockerfile.
All along, our IT and infrastructure teams around Jeff Gambera and our senior team members Tom Kraljevic and Michal Malohlava had led the automation efforts around testing, deployment, and implementation of enterprise features.
A few months later, with version 0.8 of H2O Driverless AI, we were able to reach a top 2.3% ranking in a challenging Kaggle competition out of the box in 1h. For this competition from 2016, feature engineering was especially helpful and some of our own Kaggle grandmasters had spent 2 months and hundreds of submissions to barely beat the results of Driverless AI.
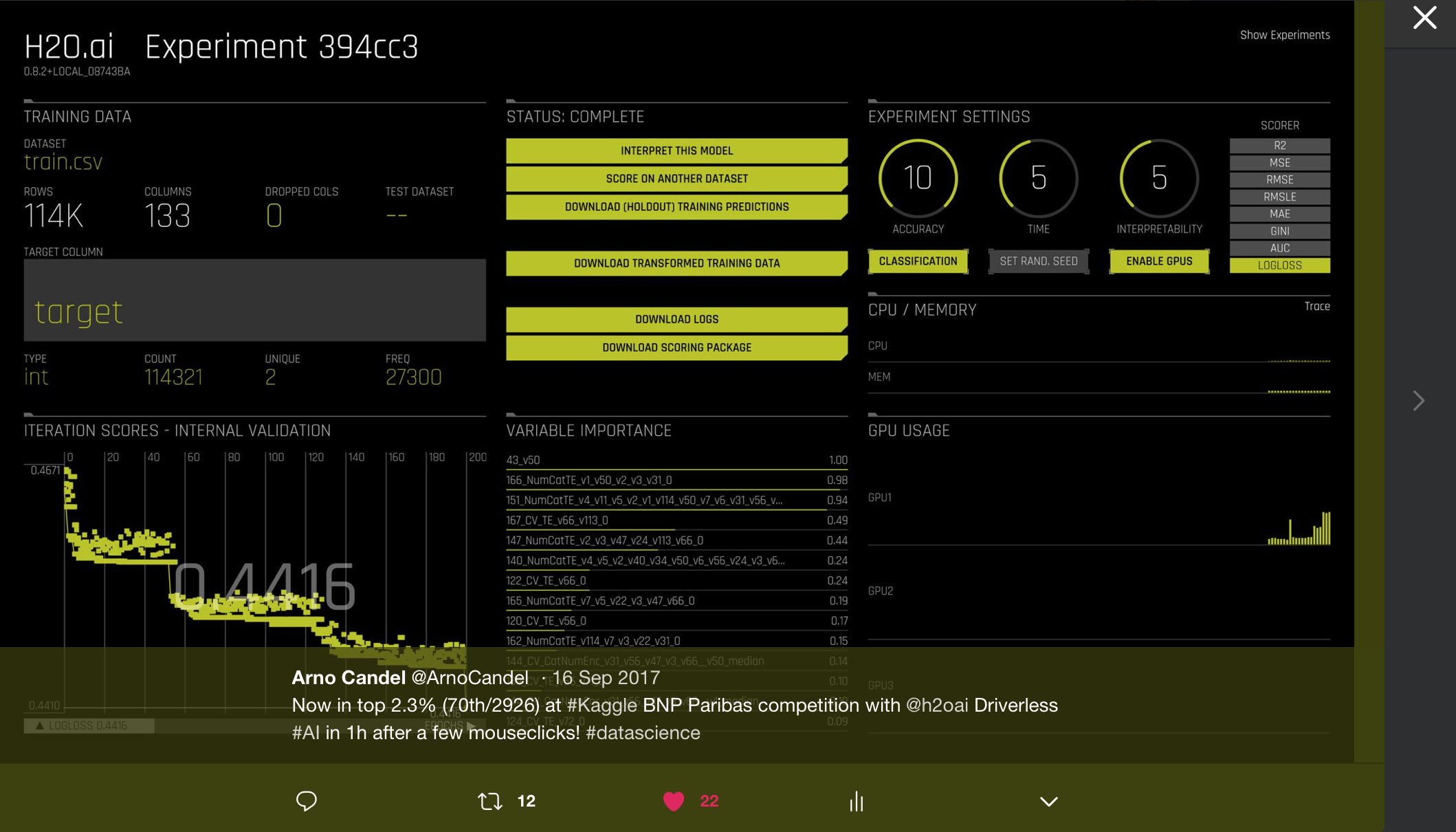
Note: The latest version 1.4.2 of H2O Driverless AI gets to 10-th place (top 0.3%) out of the box, and ties Dmitry’s original performance on this competition (he ranked 10th).
Meanwhile, our machine learning interpretability (MLI) team (Patrick, Navdeep, Megan, Wen, Mark) had come up with a full suite of interpretable techniques as part of H2O Driverless AI, and even created a booklet!

Make sure to watch Patrick’s latest presentation on interpretable machine learning in H2O Driverless AI for a great overview.
September 2017 – Driverless AI Takes Off
With all major pieces in place, we released H2O Driverless AI 1.0 in late September of 2017. We optimized it to run smoothly on a 8-GPU NVIDIA DGX supercomputer with 100 TeraFLOPS (but GPUs have always been always optional).
Driverless AI had become a digital companion for data scientists and was now able to eliminate the need of laborious manual data cleaning and preparation, validation scheme creation, feature engineering, model parameter tuning, model ensembling and it would even create automatic pipelines of the entire process ready to go to production. And it could explain its predictions in plain English. All with the click of a few buttons.
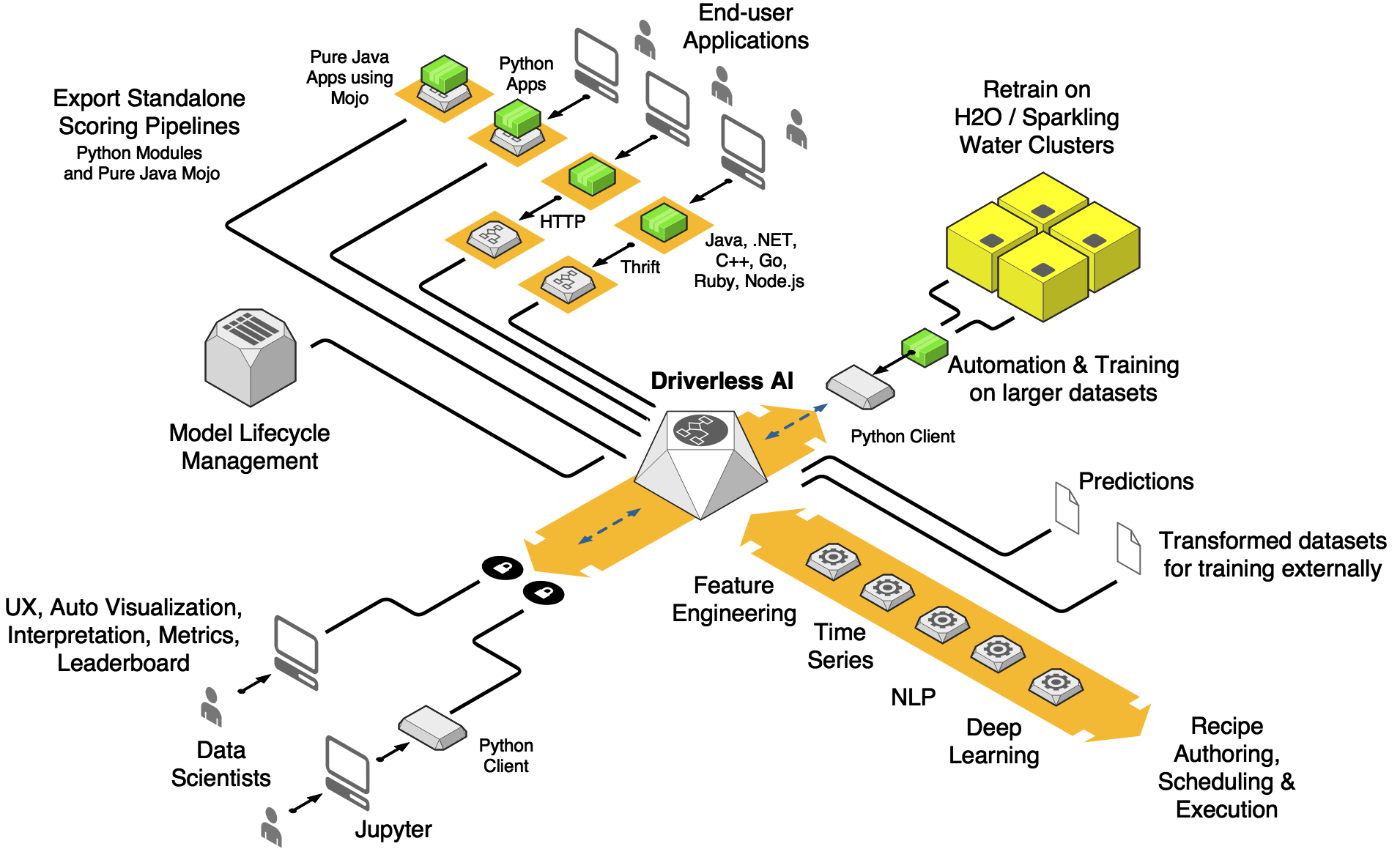
By then, the architecture and roadmap had been shaped:
Jan Gamec joined our newly established team in the Prague office and quickly became an invaluable resource for both frontend and backend work for H2O Driverless AI, and many user-facing features are the result of his contributions.
Spring 2018 – Feature Explosion and Rapid Customer Adoption
In January 2018, H2O Driverless AI 1.0.5 won the InfoWorld’s 2018 Technology of the Year Award.
Over the next few months, we added many new features, most of which were requested by customers and prospects:
- Smarter feature evolution
- Faster speed
- Improved UX, model metrics
- Multi-GPU single GBM model training
- TensorFlow deep lerning models
- GLM models
- RuleFit models
- Shapley variable importances, a breakthrough for interpretable models
- NLP recipe for text data (tf-idf, n-grams)
- HDFS, S3, Excel, Snowflake, Azure, GCP, BigQuery, Minio connectors
- LDAP, PAM, Kerberus
- Native installers (RPM, DEB)
- IBM Power support
- Java scoring pipeline
- Multitude of scoring metrics
- Automatic Documentation
- and many more …
Summer 2018 – Time-Series Recipe
In the meantime, our other two seasoned Kaggle grandmasters Marios Michailidis and Mathias Mueller had started working on a time-series recipe (AutoM&M), which had to satisfy the following requirements:
- Be fully automatic or allow the user to override parameters
- Do both classification and regression forecasting
- Handle transactional multivariate datasets with mixed datatypes
- Handle missing values
- Automatically detect seasonality and trends
- Automatically detect groups of time-series signals
- Internally validate using rolling windows
- Include an optional time gap between training and production deployment (affects the lags used)
- Allow scoring on a row-by-row basis
In the summer of 2018, we had integrated a Kaggle-proven time-series recipe based on causal splits (moving windows), lag features, interactions thereof and the automatic detection of time grouping columns (such as ‘Store’ and ‘Dept’ for a dataset with weekly sales for each store and department).
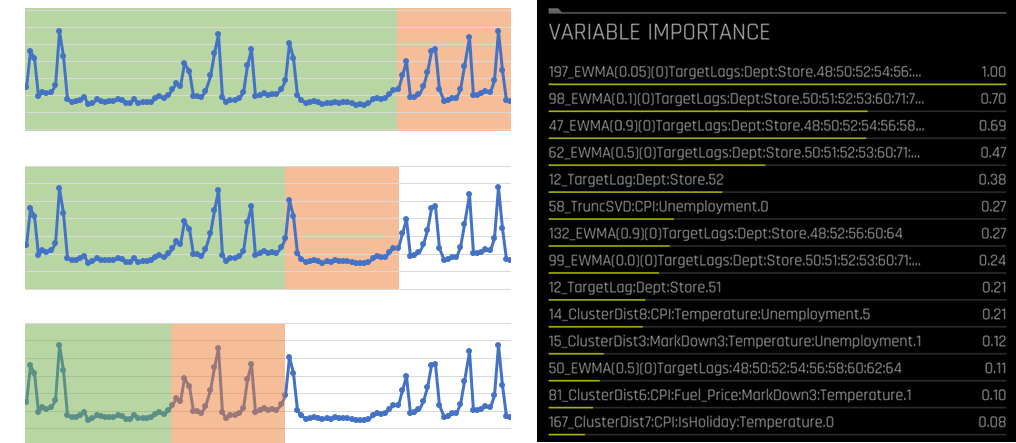
By creating these lag-based features, the algorithms are able to split the data by their past values and trends, and the results were impressive. We shipped H2O Driverless AI 1.2.0 with time-series support for H2O World New York.
You can find more information in the blog by Jo-Fai Chow on Time-Series and in a presentation by the main authors Marios and Mathias.
In future versions, we will address two remaining open issues:
- Ability to train on data with highly non-uniform time intervals
- Ability to provide fresh actual target values to the model in production to allow shorter-term lags
Summer 2018 – TensorFlow NLP Deep Learning Models
Since its first version, AutoDL had already been able to handle text columns via word count based features that were reduced in dimensionality by algorithms such as SVD or GLM.
Soon after India’s #1 Kaggle grandmaster SRK joined us in the Spring of 2018, he contributed an enhanced (and computationally more expensive) natural language processing (NLP) recipe using TensorFlow CNN deep learning models, and this recipe achieved impressive results for sentiment analysis and other related use cases. It would also benefit from the presence of GPUs with speedups of 10x and more over CPUs.
We designed the system such that every included text column in the data is transformed into out-of-fold predictions by a specific language-agnostic text model (as long as the language has space-separated tokens). This kind of target encoding enables mixing of features created by Deep Learning models and other statistical models such as GBMs or GLMs, and allows us to use these powerful word embeddings for datasets that have numeric or categorical features in addition to text features.

Make sure to watch SRK’s presentation and read Jo-Fai’s
blog on NLP to see how you can use these techniques.
Support for character-level models, pretrained embeddings and LSTMs are either work in progress or on the roadmap.
Fall 2018 – H2O AI World London
In November, we held our largest H2O World event ever in London, and we introduced various new features in H2O Driverless AI 1.4.0:
- Support for much larger datasets (some of our customers are running on 500GB+ datasets)
- LightGBM models
- Improved time-series recipes
- Smart checkpointing and automatic feature brain to avoid re-training
- kdb+ connector
- Time-series support in MLI
Now is a great time to learn from the Kaggle Grandmaster Panel and watch all excellent speaker presentations!
Right after, we welcomed our most recent Kaggle grandmaster Bojan Tunguz who is getting ready to contribute his recipe(s)!
This week, we are releasing version 1.4.2 of H2O Driverless AI which adds IBM Power support for version 1.4.
2019 – What’s Next?
We are very excited about the future of Driverless AI and about the convergence with our open-source platforms H2O-3 and Sparkling Water (with their own version of automatic machine learning AutoML).
In the months ahead, we plan on adding the following major milestones:
Open-Source Platform Convergence and Big Data Enablement
- train H2O Driverless AI models from inside H2O-3 / Sparkling Water
- deploy H2O Driverless AI artifacts inside of H2O-3 / Sparkling Water
- train large-scale H2O Driverless AI pipelines with H2O-3 / Sparkling Water backend
- algorithms for out-of-memory data sizes
Enterprise Scale
- multi-node, multi-user support
- model lifetime management
- project management and collaboration
Usability Improvements
- C++ scoring pipelines
- visual model debugging
- manual fine-control of feature engineering pipelines
Most items mentioned here are currently being worked on already, but please let us know if you have questions or suggestions for our roadmap.
Thanks for reading! I hope you enjoyed this as much as me! Now is the best time to start using H2O Driverless AI for automatic machine learning, and it’s free for academic use!
Credits
I apologize to all who didn’t get mentioned personally above, there are many more things I could have written about (Angela’s documentation, Nidhi’s support, Patrick’s PowerPC port, Megan’s AutoDoc, Nishant’s Java scoring pipelines, KK’s C++ scoring pipelines, Magnus’ benchmark system, Nikhil and Justin’s Autovis integration, Kuba’s Spark MOJO integration, Chandan’s data augmentation recipe, Nick’s cloud connectors, Neal’s brain project, Mateusz’ and Pramit’s work on MLI, Doug’s UI improvements, Michal, Sankar and Anu’s automated test systems, Dauren’s authentication and many more especially in the rapidly growing Czech team), but I have to get back to coding… so we’ll keep that for another day.
Special thanks to Mark Landry for his help in bringing the ‘data science is a teamsport’ culture into H2O.ai and for (undeservedly) making me a Kaggle master too. Thanks to Sri for giving us this opportunity, and to everyone in Team H2O.ai!
Useful Links







