







Anomaly Detection with Isolation Forests using H2O
Introduction
Anomaly detection is a common data science problem where the goal is to identify odd or suspicious observations, events, or items in our data that might be indicative of some issues in our data collection process (such as broken sensors, typos in collected forms, etc.) or unexpected events like security breaches, server failures, and so on.
Anomaly detection can be performed in a supervised, semi-supervised, and unsupervised manner.
For a supervised approach, we need to know whether each observation, event or item is aF30nomalous or genuine, and we use this information during training. Obtaining labels for each observation might often be unrealistic.
A semi-supervised approach uses the assumption that we only know which observations are genuine, non-anomalous, and we do not have any information on the anomalous observations. Therefore we only use genuine data for training. During prediction, the model evaluates how similar the new observation is to the training data and how well it fits the model.
An unsupervised approach assumes that the training set contains both genuine and anomalous observations. As labeling the data or having just clean data is often hard and time consuming, I would like to focus more on one of the unsupervised approaches to anomaly detection using isolation forests.
Loading the Data
Before we dive into the anomaly detection, let’s initialize the h2o cluster and load our data in. We will be using the credit card data set , which contains information on various properties of credit card transactions. There are 492 fraudulent and 284,807 genuine transactions, which makes the target class highly imbalanced. We will not use the label during the anomaly detection modeling, but we will use it during the evaluation of our anomaly detection.
import h2o
h2o.init()
df = h2o.import_file("creditcard.csv")Isolation Forests
There are multiple approaches to an unsupervised anomaly detection problem that try to exploit the differences between the properties of common and unique observations. The idea behind the Isolation Forest is as follows.
- We start by building multiple decision trees such that the trees isolate the observations in their leaves. Ideally, each leaf of the tree isolates exactly one observation from your data set. The trees are being split randomly. We assume that if one observation is similar to others in our data set, it will take more random splits to perfectly isolate this observation, as opposed to isolating an outlier.
- For an outlier that has some feature values significantly different from the other observations, randomly finding the split isolating it should not be too hard. As we build multiple isolation trees, hence the isolation forest, for each observation we can calculate the average number of splits across all the trees that isolate the observation. The average number of splits is then used as a score, where the less splits the observation needs, the more likely it is to be anomalous.
Let’s train our isolation forest and see how the predictions look. The last column (index 30) of the data contains the class label, so we exclude it from the training process.
seed = 12345
ntrees = 100
isoforest = h2o.estimators.H2OIsolationForestEstimator(
ntrees=ntrees, seed=seed)
isoforest.train(x=df.col_names[0:30], training_frame=df)
predictions = isoforest.predict(df)
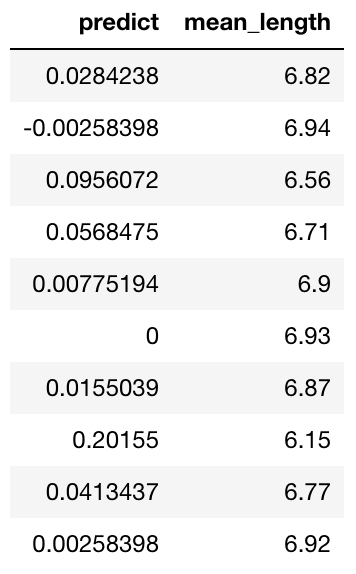
predictions
Inspecting Predictions
We can see that the prediction h2o frame contains two columns: predict showing a normalized anomaly score, and mean_length showing the average number of splits across all trees to isolate the observation.
These two columns should have the property of inverse proportion by their definition, as the less random splits you need to isolate the observation, the more anomalous it is. We can easily check that.
predictions.cor()

Predicting Anomalies using Quantile
As we formulated this problem in an unsupervised fashion, how do we go from the average number of splits / anomaly score to the actual predictions? Using a threshold! If we have an idea about the relative number of outliers in our dataset, we can find the corresponding quantile value of the score and use it as a threshold for our predictions.
quantile = 0.95
quantile_frame = predictions.quantile([quantile])
quantile_frame

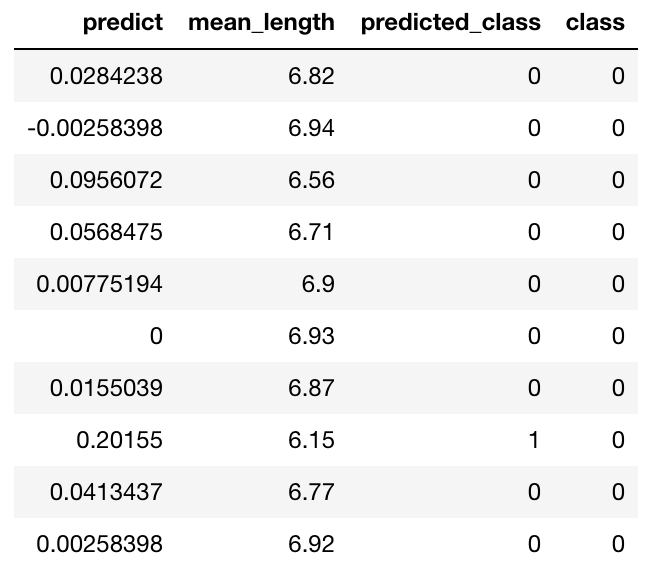
We can use the threshold to predict the anomalous class.
threshold = quantile_frame[0, "predictQuantiles"]
predictions["predicted_class"] = predictions["predict"] > threshold
predictions["class"] = df["Class"]
predictions
Evaluation
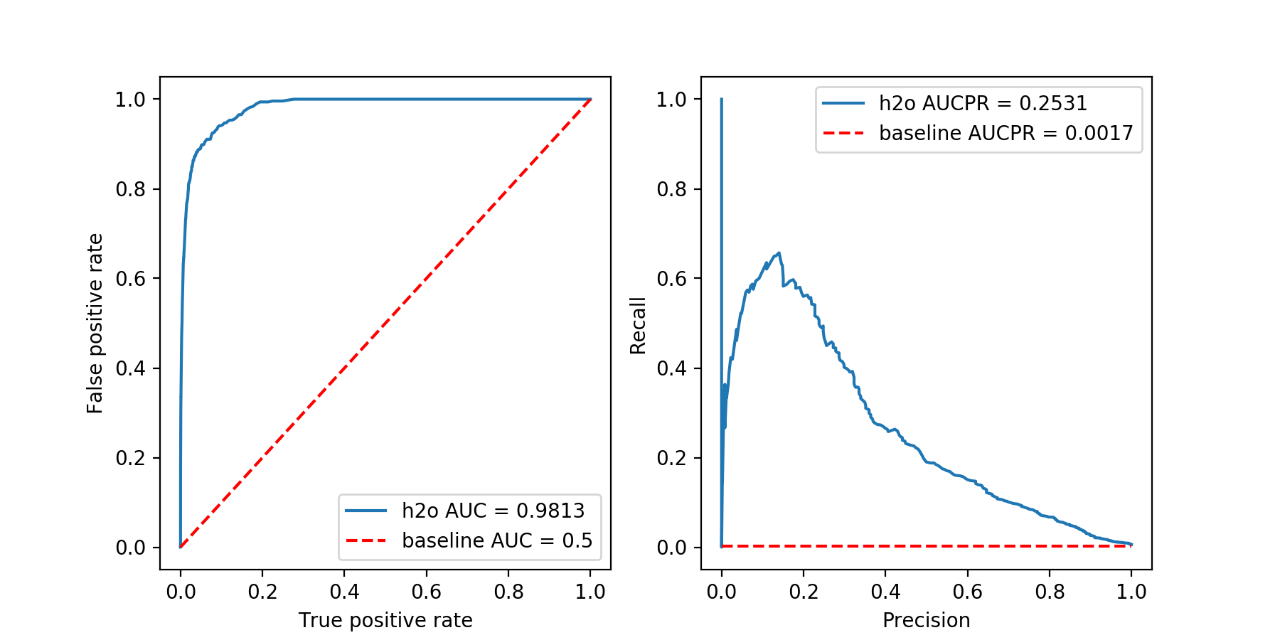
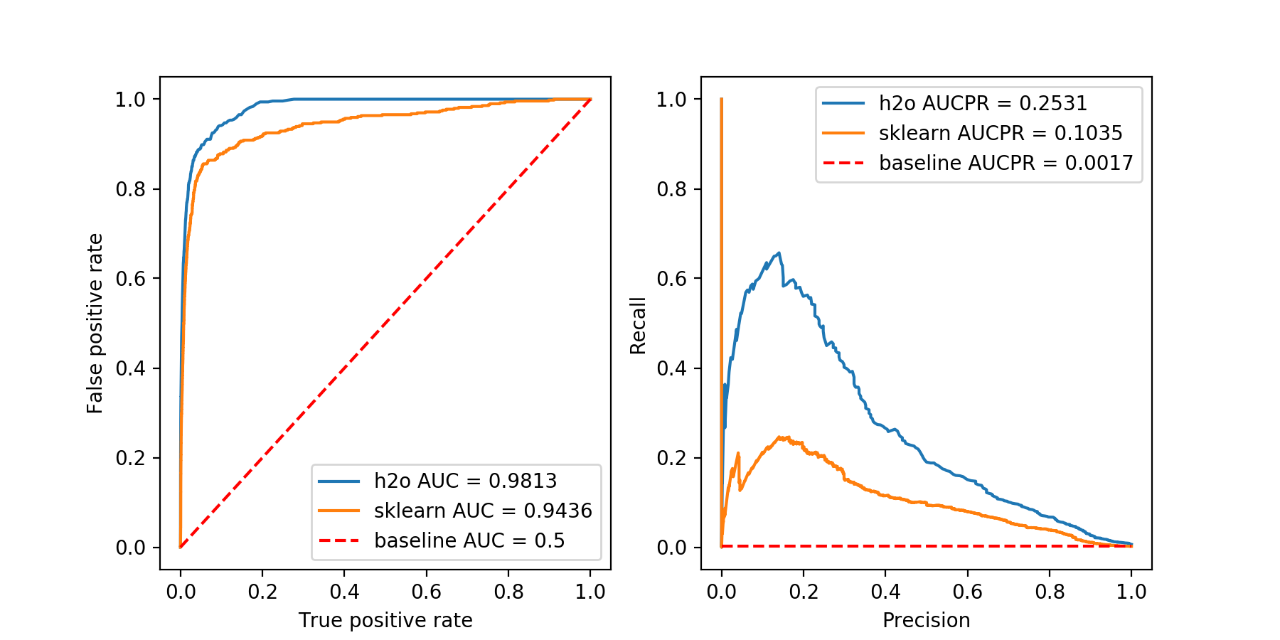
Because the isolation forest is an unsupervised method, it makes sense to have a look at the classification metrics that are not dependent on the prediction threshold and give an estimate of the quality of scoring. Two such metrics are Area Under the Receiver Operating Characteristic Curve (AUC) and Area under the Precision-Recall Curve (AUCPR).
AUC is a metric evaluating how well a binary classification model distinguishes true positives from false positives. The perfect AUC score is 1; the baseline score of a random guessing is 0.5.
AUCPR is a metric evaluating the precision recall trade-off of a binary classification using different thresholds of the continuous prediction score. The perfect AUCPR score is 1; the baseline score is the relative count of the positive class.
For highly imbalanced data, AUCPR is recommended over AUC as the AUCPR is more sensitive to True positives, False positives and False negatives, while not caring about True negatives, which in large quantity usually overshadow the effect of other metrics.
%matplotlib notebook
from sklearn.metrics import roc_curve, precision_recall_curve, auc
import matplotlib.pyplot as plt
import numpy as np
def get_auc(labels, scores):
fpr, tpr, thresholds = roc_curve(labels, scores)
auc_score = auc(fpr, tpr)
return fpr, tpr, auc_score
def get_aucpr(labels, scores):
precision, recall, th = precision_recall_curve(labels, scores)
aucpr_score = np.trapz(recall, precision)
return precision, recall, aucpr_score
def plot_metric(ax, x, y, x_label, y_label, plot_label, style="-"):
ax.plot(x, y, style, label=plot_label)
ax.legend()
ax.set_ylabel(x_label)
ax.set_xlabel(y_label)
def prediction_summary(labels, predicted_score, predicted_class, info, plot_baseline=True, axes=None):
if axes is None:
axes = [plt.subplot(1, 2, 1), plt.subplot(1, 2, 2)]
fpr, tpr, auc_score = get_auc(labels, predicted_score)
plot_metric(axes[0], fpr, tpr, "False positive rate",
"True positive rate", "{} AUC = {:.4f}".format(info, auc_score))
if plot_baseline:
plot_metric(axes[0], [0, 1], [0, 1], "False positive rate",
"True positive rate", "baseline AUC = 0.5", "r--")
precision, recall, aucpr_score = get_aucpr(labels, predicted_score)
plot_metric(axes[1], recall, precision, "Recall",
"Precision", "{} AUCPR = {:.4f}".format(info, aucpr_score))
if plot_baseline:
thr = sum(labels)/len(labels)
plot_metric(axes[1], [0, 1], [thr, thr], "Recall",
"Precision", "baseline AUCPR = {:.4f}".format(thr), "r--")
plt.show()
return axes
def figure():
fig_size = 4.5
f = plt.figure()
f.set_figheight(fig_size)
f.set_figwidth(fig_size*2)
h2o_predictions = predictions.as_data_frame()
figure()
axes = prediction_summary(
h2o_predictions["class"], h2o_predictions["predict"], h2o_predictions["predicted_class"], "h2o")
Isolation Forests in scikit-learn
We can perform the same anomaly detection using scikit-learn. The version of the scikit-learn used in this example is 0.20. Some of the behavior can differ in other versions. The score_samples method returns the opposite of the anomaly score; therefore it is inverted. Scikit-learn also takes in a contamination parameter, which is the proportion of outliers in the data set.
from sklearn.ensemble import IsolationForest
import pandas as pd
df_pandas = df.as_data_frame()
df_train_pandas = df_pandas.iloc[:, :30]
x = IsolationForest(random_state=seed, contamination=(1-quantile),
n_estimators=ntrees, behaviour="new").fit(df_train_pandas)
iso_predictions = x.predict(df_train_pandas)
iso_score = x.score_samples(df_train_pandas)
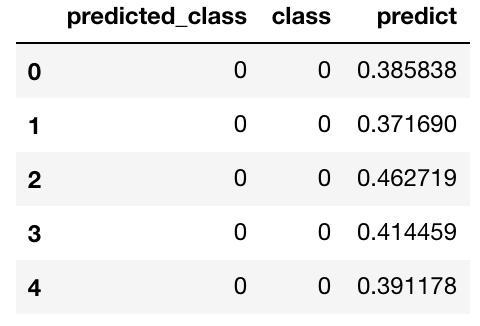
sk_predictions = pd.DataFrame({
"predicted_class": list(map(lambda x: 1*(x == -1), iso_predictions)),
"class": h2o_predictions["class"],
"predict": -iso_score
})
sk_predictions.head()
Evaluation of scikit-learn
figure()
axes = prediction_summary(
sk_predictions["class"], sk_predictions["predict"], sk_predictions["predicted_class"], "sklearn")
More Robust Comparison¶
Because there is a lot of randomness in the isolation forests training, we will train the isolation forest 20 times for each library using different seeds, and then we will compare the statistics. While 20 times might not be enough, it could give us some insight into how the isolation forests perform on our anomaly detection task.
from tqdm import tqdm_notebook
def stability_check(train_predict_fn, x, y, ntimes=20):
scores = ["AUC", "AUCPR"]
scores = {key: [] for key in scores}
seeds = np.linspace(1, (2**32) - 1, ntimes).astype(int)
for seed in tqdm_notebook(seeds):
predictions = train_predict_fn(x, int(seed))
_, _, auc_score = get_auc(y, predictions)
_, _, aucpr_score = get_aucpr(y, predictions)
scores["AUC"].append(auc_score)
scores["AUCPR"].append(aucpr_score)
return pd.DataFrame(scores)
def iso_forests_h2o(data, seed):
isoforest = h2o.estimators.H2OIsolationForestEstimator(
ntrees=ntrees, seed=seed)
isoforest.train(x=data.col_names, training_frame=data)
preds = isoforest.predict(data)
return preds.as_data_frame()["predict"]
def iso_forests_sklearn(data, seed):
iso = IsolationForest(random_state=seed, n_estimators=ntrees,
behaviour="new", contamination=(1-quantile))
iso.fit(data)
iso_score = iso.score_samples(data)
return -iso_score
h2o_check = stability_check(iso_forests_h2o, df[:30], h2o_predictions["class"])
sklearn_check = stability_check(
iso_forests_sklearn, df_train_pandas, sk_predictions["class"])
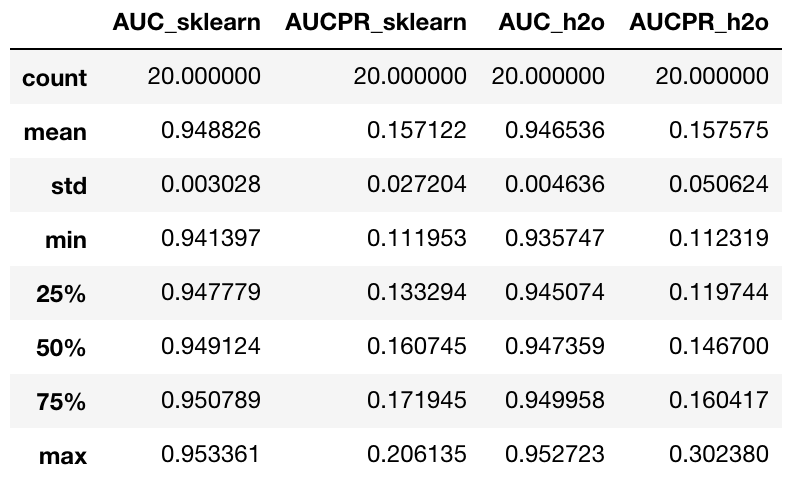
sklearn_check.join(h2o_check, rsuffix="_h2o", lsuffix="_sklearn").describe()
Comparison Results
Looking at the results of the 20 runs, we can see that the h2o isolation forest implementation on average scores similarly to the scikit-learn implementation in both AUC and AUCPR. The big advantage of h2o is the ability to easily scale up to hundreds of nodes and work seamlessly with Apache Spark using Sparkling Water. This allows you to process extremely large datasets, which might be crucial in the transactional data setting.
Conclusion
We have learned about the isolation forests, their underlying principle, how to apply them for unsupervised anomaly detection, and how to evaluate the quality of anomaly detection once we have corresponding labels. Even though we did not go deep into internal parameters of the isolation forest algorithm, you should now be able to apply it to any anomaly detection task you might face. I hope you have enjoyed this journey as much as I did.








