







H2O for Inexperienced Users
Some background: I am a rising senior in highschool, and the summer of 2018, I interned at H2O.ai. With no ML experience beyond Andrew Ng’s Introduction to Machine Learning course on Coursera and a couple of his deep learning courses, I initially found myself slightly overwhelmed by the variety of new algorithms H2O has to offer in both its open source and enterprise software. But by exploring various resources, by the end of the summer, I was able to use Driverless AI and H2O-3 algorithms in the TGS Salt Identification Challenge on Kaggle. In this blog post, I will relate my experiences and learnings from my time at H2O.ai as well as resources to learn H2O and data science for those who are new to this.
Getting Started
H2O-3
To get started with H2O, I first downloaded the H2O-3 package along with the Python client. Though the installation instructions are straightforward, when doing installing and using the Python client, ensure that:
- The H2O Python installation and the downloaded package match versions.
- H2O is running Java 8
If you do not wish to use Python, H2O-3 has a GUI API, H2O Flow, which can be accessed on a browser; the python client was easy to use and flexible, with intuitive commands and other python benefits such as numpy , pandas, and opencv.
After getting H2O-3 working, the next task was getting familiar with its functionality. Useful resources for this include:
- The documentation: It is definitely worth reading pages available in the sidebar (skip or skim at your discretion). The documentation gives an overall view of what you can do with H2O-3 as well as details and explanations regarding implementation. Example code can be found on some pages in both R and Python. If example code is not available on some pages — for example, on the Deep Learning page — it is probably available in the GitHub repository (most likely in the tutorials folder; you could search through the repository if not easily findable)
- H2O-3 GitHub: Go through the tutorials for the project you have in mind. Go through some more to see other functions and algorithms that you could include. I found the example code in the tutorials very useful in learning how to use each function. The source code was interesting to read through. Give it a read if you want to understand how everything is implemented; although to understand how to use everything, it would be easier to go through the documentation since the source code is quite long to read and interpret.
- Coursera: H2O has a course on Coursera, where you can access the material for free, but need to pay for assignments. Though I did not give this a try, if you would prefer a more structured approach, give this a shot.
As I became more familiar with H2O-3, I went through the logs printing to the terminal window where the h2o instance was launched via Java as I ran various algorithms. This was also quite helpful in understanding what it was doing, monitoring progress, and finding potential improvements in data or model hyperparameters.
Starting with H2O Driverless AI
I got started with Driverless AI (DAI) in the same way as H2O-3. I downloaded and installed DAI as per the installation instructions . It was quite straightforward, but it is worth noting that if you do not have enough RAM on your machine (the instructions mandate a minimum of 10 gb for DAI to run), try running DAI anyway, it may still work. I allocated 4 gb on a Mac with 8 gb of RAM, and it was still able to run.
To familiarise yourself with DAI, first go through all pages in the documentation sidebar. Model interpretation and transformations are unique to DAI. To understand model interpretation, I tried to understand LIME by looking at its GitHub repository and this article . The original paper is worth a read too.
DAI is very intuitive to use. It was quite easy to understand how to use it. It is, after all, built for non-data scientists!
Ensembling
H2O-3 AutoML (as well as some inherently ensembled models) and DAI ensemble models to improve performance. Ensemble models are also used frequently on Kaggle. This article explains ensembling conceptually, and this blog post shows how to implement it. Related: mlwave.com is a great resource to learn machine learning concepts, uses, and workflows from top Kagglers and data scientists. I highly recommend reading it; the articles are very interesting and might be helpful to your data science project.
Small Project
I started experimenting with DAI and H2O-3 with a day trading use case by downloading 24 months worth of Tata Steel equity data from the (Indian) National Stock Exchange. I intended to use the previous day’s markers and current day’s opening price to predict the current day’s close price.
I first processed this dataset by shifting elements in marker columns one day such that the current day’s closing price was in the same row as the previous day’s markers — this was not the correct way to do time series; DAI’s time series feature processed the data automatically and appropriately. I then ran DAI on this dataset. Since H2O-3 algorithms ran much faster, I was also able to train multiple H2O-3 models on this dataset while DAI ran. Training RMSE scores were around 10 with the H2O-3 algorithms and 9.1 with DAI, and test scores were around 213 on small test datasets, which made the model useless for any day trading application.

In search of ideas to boost model performance, I found this video by Marios Michailidis on how to use DAI on Kaggle. He used DAI and other algorithms as shown below to stack models and make the most of DAI’s feature engineering :
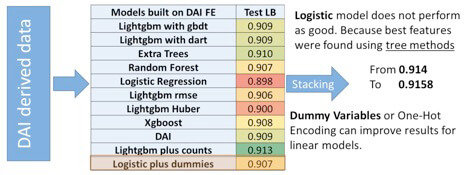
In an attempt to follow this, I first fed DAI derived data with the extra features (but with ground truth price values ie. the close price column from the original dataset) to various H2O-3 models, which displayed more diversity, and then fed their predictions to DAI (the final model). This was more promising in the train phase with an RMSE of around 3.5 but performed worse on the test dataset with a score of around 288. . Look through the aforementioned blog post to see how to do it correctly.
Later, I tried DAI’s time series feature on the unedited dataset, and its performance drastically improved to ~0.05 train RMSE and ~6 test RMSE. However, even with this improved performance, the model’s substantial performance decrease on the test set suggests that it didn’t have enough data to create an accurate model.

Kaggle
After trying out and familiarising myself with H2O-3 and DAI, since I could not find enough data for Tata Steel to make a better model, I looked to Kaggle , a data science competition platform. The TGS Salt Identification competition seemed interesting and a sizeable dataset. This competition involved identifying whether a subsurface target is salt or not given seismic data (in the form of images) and the depths of each image — in other words, the location and boundaries of salt on a seismic image.
I highly recommend you look at Kaggle even if you do not intend to participate in competitions as it has great resources for people new to data science, including datasets , discussions (a section for beginners), computing resources, and code (kernels ).
Helpful Python Modules
Python has a variety of modules that make data manipulation much easier. Take a look at numpy and pandas for computation and data manipulation, csv for csv reading and writing, and opencv when working with images.
Dataset generation
Since H2O does not accept image data, I generated a dataset of the following column format, where each row corresponds to a pixel on an image using this script :
| Id (string) | depth (real) | greyscale pixel value (real) | salt ground truth (bool / enum) |
|---|
Feeding this data to DAI was quite straightforward; I just uploaded it using the upload file button. With H2O-3, however, it needed to be compressed, else Python would throw [Errno 22] Invalid argument. Note: Python 3 seems to struggle with files over 2-4 gb ; H2O.ai will fix this bug by upgrading their import libraries.
The python script created a train set of 3600 images’ pixels, validation set of 400 images’ pixels, and a test set of 18000 images’ pixels; these test predictions would then be submitted on Kaggle.
DAI and H2O-3 Algorithms
To prevent the algorithms from memorising the data, the id column was dropped before training. Since the train and test datasets were quite large (~41 million rows and ~183 million rows respectively), without a GPU, DAI took a long time to train. In this time, I tried the H2O-3 DeepLearningEstimator. For both I used the AUC metric as the scorer, and enabled Tensorflow models and RuleFit support (in the expert settings menu) for the DAI final pipelines. DAI achieved ~0.75 train AUC, and H2O-3 Deep Learning ~0.72.
The predicted pixel values were converted to RLE encodings mapped to ids as required by the competition scorer using this script . Credit to rakhlin for the numpy array to rle function found here . The Intersection over Union (IoU) scores of the Deep Learning and DAI models on the test dataset, as scored by Kaggle, were as follows:
| Model | IoU |
|---|---|
| H2O-3 Deep Learning | 0.263 |
| DAI | 0.176 |

Lack of features
Potentially the biggest hindrance to model accuracy was the lack of features. Datasets only had two features for each pixel (since id was dropped). This was remedied by adding more features including pixel position, neighbouring pixel greyscale values, and picture greyscale maximum, minimum, and average.
This, however, exposed yet more hardware limitations as the train, validation, and test files (particularly the test file) swelled from 4 columns to 13. DAI took a long time to run, my laptop ran out of RAM, and Python did not support uploading large files, all slowing progress.
Resources
The Kaggle forums were incredibly useful for possible avenues to improve models, be it by understanding and augmenting the data, exploring more appropriate models, or refining models. Other than that, whenever a problem arose, Googling it usually led me to research papers that had some answers (or were otherwise at least interesting), Stackoverflow, or Kaggle discussions.
I also got a lot of ideas and suggestions from Megan at H2O for how to improve model performance, including additional features and autoencoding (see below). H2O can also be a great resource for you to learn data science and improve your models.
Ideas going forward
Feature engineering is usually a key part of Kaggle competitions (as I have learned from Kaggle forums), so including more features could quite likely improve model performance. Such features could include pixel distance to sand clusters, general shapes of sand clusters, or maybe more neighbours’ salt truths. Try and find more features.
Autoencoders or GLRM’s could also be used to denoise the input image and / or the predictions. Upon examining the initial (2 feature) DAI train predictions, I noticed a lot of noise, particularly on images that should be empty. Kaggle has implemented the IoU metric such that if any salt is predicted on images that should be empty, that image receives a score of 0. Running test predictions through an H2OAutoEncoderEstimator trained on the train predictions and train set should reduce noise and remove stray pixels on otherwise empty images.
Empty images could also be caught by running the input image through another model which first checks whether it is empty. If predicted empty, rather than risking a few pixels, there would be 0 true pixels predicted on that image.
Other models that are more suited to images may also provide a better solution. UNets seem to be quite successful in the competition as evident in the forums. Other convolution networks should also provide a boost in both performance and speed over the regular deep neural network model. As suggested by Sri, a GAN approach could also work as the model needs to generate a mask image.
In terms of speed, Cython seems a promising avenue to speed up dataset processing. Greater efficiency and fewer hardware constraints would also make ensembling (stacking / blending) a more viable avenue to improve model performance.
If you have the time, desire, and computing resources, pick up the baton and try the competition out!
Miscellaneous Learnings
Command line tricks
Familiarity with the command line, while not required to work with H2O, makes most tasks easier. For me knowing how to navigate files, launch Java, use Python and pip, connect to remote machines and run tasks on them was sufficient.
Remote machines
If you are using DAI or H2O on a remote machine (or anything else for that matter), these commands may be helpful:
wget : download to the machine
ssh : connect to the machine’s command line
Byobu can be used to preserve remote sessions (you can have DAI or H2O-3 running on the remote machine even when disconnected) and is very easy to use.
Machine for machine learning
As noted earlier, I ran into numerous hardware limitations in both viability and speed. Setting up a machine for machine learning would make everything easier and faster. This article may be helpful if you are looking to build one. Note for the GPU: GPU’s exponentially speed up H2O performance, but H2O’s GPU parallelisation is built using CUDA (as are many other scripts used in ML), so when deciding on a GPU, get one with CUDA.
Going forward
After becoming familiar with H2O, a good next step could be to explore and understand more algorithms, so that you can apply the appropriate algorithms to use cases. This could also improve the results of ensembling models. Additionally, studying more data science allows for better understanding and manipulating datasets, which too would improve model performance. Finally, just reading papers, Kaggle discussions, and keeping up with H2O documentation would be interesting and fun ways to learn more and generate new ideas.







