







How Sparkling Water Brings H2O to Spark
This post provides a high-level introduction to the current integration plan between H2 O and Spark. This is an ongoing engineering effort involving collaboration between the open source teams, and describes what is currently underway.
1. Overall Approach
The first question one might ask is “Why”? What does one, as a user, gain from trying to put Spark and H2 O together?
Spark is a really elegant and powerful general-purpose open source in-memory platform that’s gaining tremendous momentum. H2 O is an in-memory application for Machine Learning that is reshaping how people apply math and predictive analytics to their business problems.
Wanting to make these two best-of-breed open source environments integrate more tightly with one another is just a natural thing to do. Customers want to use Spark SQL to make a query, feed the results into H2 O Deep Learning to build a model, make their predictions, and then use the results again in Spark. We get asked about this type of use all the time, and the answer is simple: for any given problem, the better your tools interoperate, the better your experience is going to be. And more specifically for Machine Learning, we want you to choose and use your favorite algorithm for a problem easily, whether it is from H2 O or MLlib, or roll-your-own.
The rest of this discussion looks at “How” we do this.
For those of you that have been following the Sparkling Water effort since its inception, one thing should immedately jump out at you: no more Tachyon required. The first cut of Sparkling Water required intermediate storage (we chose the Tachyon in-memory filesystem project) to transfer data back and forth between Spark RDDs and H2 O. With this second cut of Sparkling Water, H2 O runs directly in a Spark JVM and this intermediate has been eliminated.
Furthermore, we added the H2 O RDD as a new RDD type in Spark, and made it really easy to move data back and forth between Spark RDDs and H2 O RDDs. We run the H2 O software directly in the Spark cluster using the spark-submit approach. A Sparkling Water application jar file is passed directly to the Spark Master node and distributed around the Spark cluster. (Conceptually, this is very similar to the “hadoop jar” approach of launching an application on Hadoop.)
The next sections go into more detail on how this all works.
2. Changes Required to Spark
[UPDATE Nov. 1, 2014] As of Sparkling Water version 0.2.1-19, no changes to Spark are required! Use standard Spark 1.1. (And this section is now ~~struck out~~.)
~~A few small changes (about 20 lines of code) were needed to the Spark interface to get things running. These changes are related to Sparkling Water cluster formation (which is tricky because many Spark operations are lazy DAG elements, but the cluster needs to be prepared before work can be assigned to it). The approach we are taking is to embed a full H2 O instance inside the Spark Executor JVM, and the H2 O instances need to find each other during application initialization.~~
~~We have been using an open source fork of Spark 0xdata/perrier git repository to experiment with the needed modifications. The goal here is to work with the Spark team and put together a sufficiently general set of changes that get accepted back into the Spark main code line.~~
~~Michal Malohlava has created Apache Spark JIRA 3270 to track the discussion around ideas for an application extension API for Spark. This is very fluid at this point, with Spark contributors providing feedback. (Much appreciation to Xiangrui Meng, Josh Rosen and Patrick Wendell for their guidance and suggestions!)~~
~~The next section describes the high-level approach for how the Sparkling Water application starts up. For the low-level details, which are still being hashed out, stick to the JIRA above.~~
3. Sparkling Water Application Lifecycle
One of the really neat aspects of this integration is the ability to leverage the existing Spark deployment and run the Sparkling Water application directly on the Spark cluster.
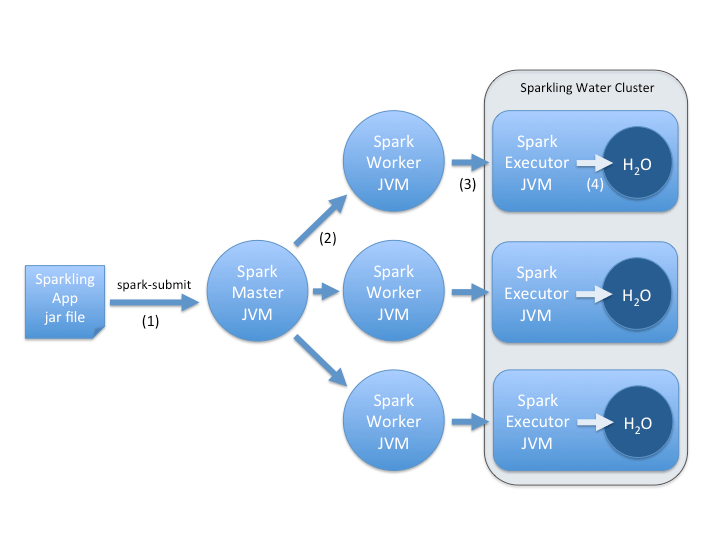
We use the existing spark-submit command to submit the Sparkling Water application jar file to the Spark Master node (see Step (1) in the diagram below).
Step (2) shows the Master JVM distributing the application jar to each of the Spark Worker nodes. This is a free side-effect of adopting the “spark-submit” approach.
Step (3) shows each Spark Worker (which isn’t actually doing any of the CPU or Memory intensive work) starting a Spark Executor JVM. It’s the Executor JVMs that really end up training models and making predictions.
Step (4) shows each Executor starting an H2 O instance within the Executor. This H2 O instance shares the JVM heap with the Executor (since it is embedded), but creates its own Fork/Join threads for CPU work. The Sparkling Water cluster fully forms once all the Spark Executor JVMs bring up their embedded H2 O instances. This requires a rendezvous point and is one of the tricky aspects of implementing the integration (since many Spark operations are lazy). Essentially the application launch process needs a barrier to make sure the Sparkling Water cluster is fully formed before it can do any work. How to do this is one of the interesting discussion points in JIRA SPARK-3270.
After completing the above steps, the application’s main Scala program runs. You now have full access to both the Spark and H2 O environments and one unified program flow of control.
3.1. Sharing a Spark Cluster
The decision to use the “spark-submit” approach results in a number of interesting application properties.
Each user launches his own Sparkling Water application. In fact, a user can launch many as he wants. Multiple versions can live side-by-side in distinct application contexts, even for a single user, and individual Sparkling Water applications are versioned independently. This makes it easy to keep a production workflow stable while doing a POC on the latest H2 O software with the latest algorithms and features.
One potential drawback is that data within Spark is not shared between Spark contexts, and data within Sparkling Water is not shared between Sparkling Water application instances. This can be good or bad depending on your perspective (and the size of the data). It’s bad if you really don’t want to duplicate the data, but dedicated JVMs and resource isolation are good for production stability and failure containment.
4. Sparkling Water Data Distribution
One question people often ask in the context of Sparkling Water is “what happens to my data”? Let’s take a high-level look at what happens for the common workflow of an SQL query followed by training a model (see the diagram below).
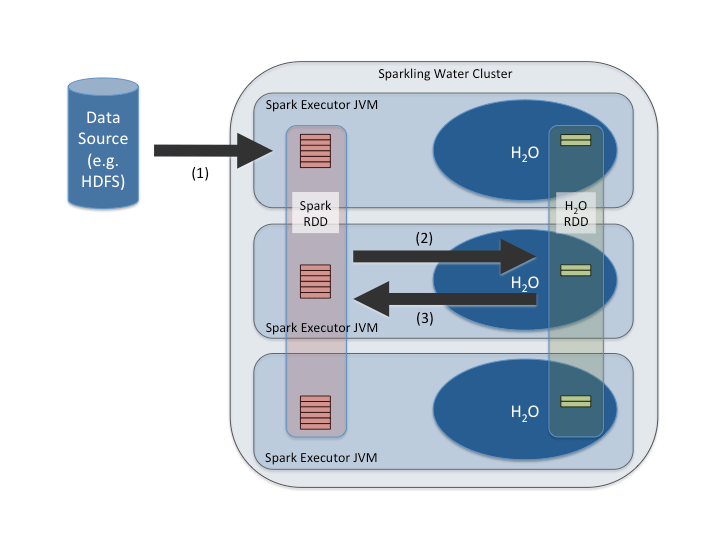
Step (1) shows how Spark SQL reads in data from a data source like HDFS into a Spark RDD. This is a totally vanilla Spark operation. The data lives in the Spark Executor JVM.
Step (2) shows conversion from a Spark RDD into an H2 O RDD. In the following example from Michal , this is driven by Scala code. An H2 O RDD is really a thin layer on top of an H2 O Frame, and an H2 O Frame is the column-compressed representation of data that H2 O algorithms operate on. (The engineering term for an H2 O Frame is a Frame composed of “Fluid Vectors”, where a Vector , or Vec, is really just a column.)
Each column in the H2 O Frame representation is compressed independently, and since values within a column are often similar, this frequently results in really good compression ratios.
At this point there are two copies of the data, each with a different in-memory representation: one is a pure Spark RDD, and one is an H2 O Frame (with an H2 O RDD thinly wrapping it so that it’s accessible to Spark). (Note the third Tachyon copy from the previous Sparkling Water incantation is gone now!)
Now we use H2 O for what H2 O does best: train models and use them to make predictions. Here is where you run Deep Learning, GBM, Random Forest , GLM, etc. Predictions are stored in a new H2 O Frame (with a new corresponding H2 O RDD).
Step (3) shows conversion of the new H2 O RDD containing predictions back into a pure Spark RDD. From there, the predictions can flow into the next stage of your data pipeline if it’s running on Spark.
5. Summary
Sparkling Water is for people who are interested in using the best capabilities of both Spark and H2 O in one environment. Development is very active and the intent is to provide the best experience for both the developer and user communities. Which, if you’re still reading, means you!
Tell us about this or other topics that interest you by writing to h2ostream@googlegroups.com .







