







A K/V Store For In-Memory Analytics, Part 2
This is a continuation of a prior blog on the H2O K/V Store, Part 1.
A quick review on key bits going into this next blog:
- H2O supports a very high performance in-memory Distributed K/V store
- The store honors the full Java Memory Model with exact consistency by default
- Keys can be cached locally for both reads & writes
- A typical cached Key Get or Put takes 150ns
- A cache-missing operation requires network traffic; 1 or 2 UDP packets, or a TCP connection for large payloads.
- Single-key transactional updates are supported
- The Keys are pseudo-randomly distributed, removing a “hot-blocks” problem
- There is no “master” Node; the cluster is fully peer-to-peer
- Individual Keys have a “Home Node”, responsible for ordering conflicting writes to the same Key; the Home Node varies from Key to Key
- Network operations are built on top of a reliable RPC mechanism built into H2O
The code for all of this can be found in the H2O GIT repo:
https://github.com/0xdata/h2o/blob/master/src/main/java/water
The Distributed K/V Store (hereafter, the DKV store), is similar to the hardware cache-coherency protocols MESI , but altered to better match the software layer. In this hardware analogy, a Key is akin to an address in memory, a Value’s payload is akin to the data stored at that address – and the Value itself is more like the hardware cache coherency bits. These bits are not directly visible to the X86 programmer, but they have a profound impact on the (apparent) speed of memory, i.e. the cache behavior. As is typical for this kind of thing, the actual implementation is basically a distributed Finite State Machine .
Keys have a “Home Node ” (pseudo-randomly assigned – the Home Node is different for each Key). Keys keep a little bit of state cached (mostly Home Node and a proper hash) but do not directly track coherency – that honor is given to the Values.
On the Home Node then, a Value tracks which other Nodes have replicas of this Value, and is responsible for invalidating those replicas when the Key is updated to a new Value. Values also are used to force ordering of writes to the same Key from the same non-home writer – 1 JVM can only have a single outstanding write to the same Key in flight at once (although there’s no limit to the number of pending writes to unrelated Keys). Hence parallel writes to unrelated Keys all work in parallel – the limit being the network bandwidth instead of the network latency.
Each Value holds a single AtomicInteger for a read/writer-lock , and a NonBlockingSetInt (really just a fast concurrent bitset), and a pointer to the user’s payload. The R/W lock holds the count of pending Gets in-flight, or -1 if the Value is write-locked. The pending-Gets count is typically zero, only going up when a new cached replica is being set in some Node; once the remote Node has the replica (completes it’s Get) the pending-Gets count will fall again. The bitset holds the set of Nodes replicating this Value. Gets are implemented in TaskGetKey.java , and are an instance of H2O’s reliable RPC mechanism in RPC.java .
On a non-home node, the Value’s R/W lock field only holds a flag indicating that the Value is being overridden by a fresh local write, or not.
For a running example, lets assume a 4-node cluster. The cluster members are called A ,B ,C , and D . We have a single Key, “K1” and start with a single Value “V1”. When writing a Value, we’ll follow with the count in the R/W lock, and a list of Nodes in the replica list. Example: “V1[2,A]” means Value V1 has 2 pending-Gets, and is replicated on Node A .
A quiescent Value, with no Gets-in-flight and no replicas:
Actually, this is a 4-node cluster with K1 & V1 on Node A and not on the other nodes. Hence a better picture is:
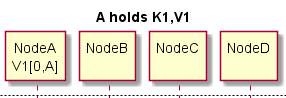
Node B has K1 and does a Get. This misses in B ‘s local K/V store (see DKV.java), so B does a remote Get (TaskGetKey.java). K1’s hash (available directly from K1 without talking to any other cluster member) tells us that K1’s home is Node A . Hence B fires off a TaskGetKey from B to A requesting a replica of K1. Here’s the flow:
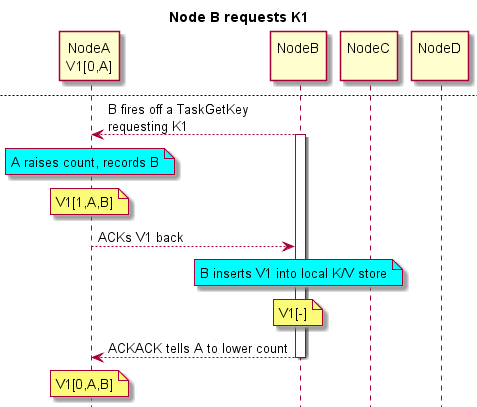
Note that once Node B receives V1, the thread in B waiting for it can immediately begin processing V1. The ACKACK is sent back asynchronously. The request for K1 fits in a UDP packet. Assuming reply V1 does as well, B only has to wait for a round-trip UDP packet send & receive before getting his data. Assuming Nodes C & D make the same request:
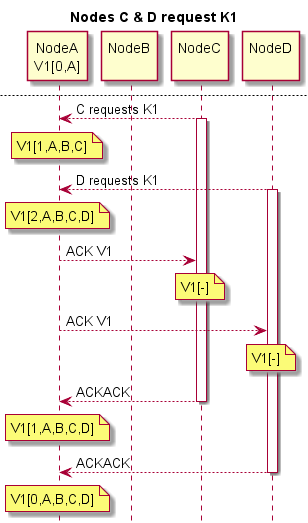
At this point any Node in the cluster can retrieve V1 from K1 at no more cost than a hashtable lookup.
What happens when C wants to write a new Value V2 to Key K1? C writes V2 locally, then sends V2 to A . A then resolves any conflicting writes (none here), and invalidates the copies B & D have. Future reads by B & D will then reload the updated value from A . Finally, C gets notification that his write has completed. Here’s the flow:
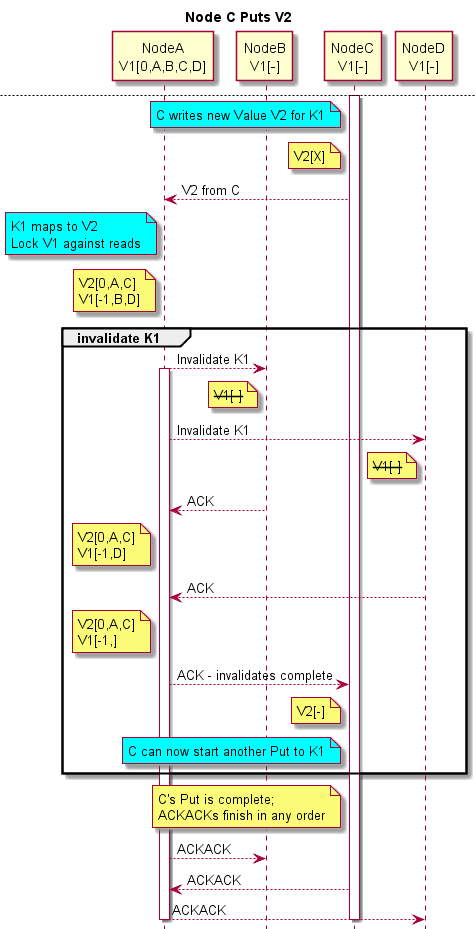
Let’s work through this diagram a little.
- Node C writes V2 locally. This means parallel threads within C can see the update immediately. Also the writing thread can choose to do either a volatile write or not. For a volatile write, the writing thread will block until it receives an ACK from Node A that the invalidates are complete. For non-volatile writes, this is a fire-and-forget operation, although a future unrelated volatile write might need to block until C receives the ACK from A.
- Node C writes V2 with an “X” in the R/W-lock – a flag indicating that the write of V2 is in-progress. Node C is not allowed to start ANOTHER write to K1 until this write completes; further writes (of K1 from C) will block. Hence Node A does not have to handle UDP out-of-order writes from C. Writes to other Keys are not blocked.
- Unlike a remote Get, the payload goes out in the initial send from C to A; the payload size determines if this is via UDP or TCP. The ACKs are all small, and always go via UDP.
- Value V1 in Node A is tracking the replicas, very akin to what a hardware cache mechanism would do. Upon receiving the write from C several things happen in short order (but distinctly spaced in time): (1) A single atomic replace operation in A‘s local K/V store dictates which of several possible racing writes “wins” (at this point in time racing unrelated readers in A can see either V1 or V2; both are valid responses since the readers are racing). (2) V1 is locked against future reads (at this point in time, any racing readers finding V1 will fail and upon retrying find V2); locking is done by setting the R/W-lock to -1. (3) V2’s replicas are set to the sender C (who must have had a copy to send it!) and the receiver A, and these Nodes are removed from V1’s replica list.
- Now A can start invalidate replicas around the cluster. Note that if there are none, this operation takes no time! Otherwise A sends out invalidate commands (to B & D here) and waits for the response…. thus causing C to wait until the cluster-wide invalidates are done.
- As soon as the last invalidate is ACK’d back to A, A will ACK back to C.
- The ACKACKs here can happen in any order and are not required for proper coherency & ordering; ACKACKs are used by the reliable RPC mechanism to know that the ACK made it.
Let’s talk a little about the performance here. What operations are fast, or slow – and why?
- All Things Cache Locally. In the absence of conflicts, everything caches locally and no network traffic is required to make forward progress. Cached Readers take about 150ns a pop. Cached writes can all go fire-and-forget style (bound by network bandwidth and not latency), and a Reader following a Writer goes fast, and “sees” the write.
- Readers Never Block. If you look in the above flow, the only time a Reader blocks is on a cache-miss: the reader simply has to wait for the network to deliver the bytes. Note that a Reader who misses locally and is blocked on the Home Node delivering a result, does NOT in turn wait for the Home Node to finish any other network operation. In particular, the Home Node can deliver a valid result even while Invalidates are in-flight.
- Unrelated Writes do not wait on each other. Parallel unrelated writes go as fast as the network allows (bandwidth, not latency).
- Writes can (rarely) Block on Readers. Taking the write-lock requires all pending-Gets to complete. Max of 1 pending-Get per Node, and they all complete in parallel – so this cannot take longer than the time to send the old Value around the cluster.
- Back-to-back Writes to the same key Wait. Each Node can only have 1 pending write to the same Key at a time. Back-to-back updates will block until the first one fully completes.
- Distributed writes to the same key are ordered, by the Home Node’s atomic replace operation. However, they will typically be handled very fast after the first one – once the invalidates are done, a series of Puts will be ordered by the replace operation as fast as the memory system allows, and the ACKACKs can complete in any order (again, network bandwidth not latency).
These common use cases do not block, and go at either network speeds or memory speeds:
- Parallel Reading Local Big Data. Cached locally as-needed, reads at memory speeds
- Parallel Reading Remote Big Data. Uses full network bandwidth, and then cached thereafter
- Parallel Writing Local Big Data. Streaming writes use full memory bandwidth, no network
- Parallel Writing Remote Big Data. Streaming writes use full network bandwidth, not any round-trip latency
We have yet to talk about:
- Resolving racing writes
- resolving racing readers & writers
- Slow network reordering events (reliable RPC turns unreliable network into slow network w/reordering)
But… I think I’m out of space!
Comments welcome as always,
Cliff







