







Make your own AI — Add Your Game to Auto-ML Models
When Features and Algorithms compete, your Business Use Case(s) wins!
H2O Driverless AI is an Automatic Feature Engineering /Machine Learning platform to build AI/ML models on tabular data. Driverless AI can build supervised learning models for Time Series forecasts, Regression , Classification , etc. It supports a myriad of built-in feature engineering transformers to work with numeric, categorical, dates and text datatypes and runs algorithms that are curated by Kaggle Grandmasters. The end result is, in a very short time, data scientists and business analysts can build highly accurate AI/ML models and integrate with production apps, leaving all the heavy lifting to Driverless AI.
This is great for most businesses who are struggling to hire talent, create trust, explainability and reduce time to operationalize and evaluation bias in AI/ML models, across multiple groups.
Driverless AI has tons of feature engineering transformers that go to work when it sees numeric, categorical, timestamps, text, etc., in the data. The explanations of these transformers are here. A screenshot on the built-in ones:
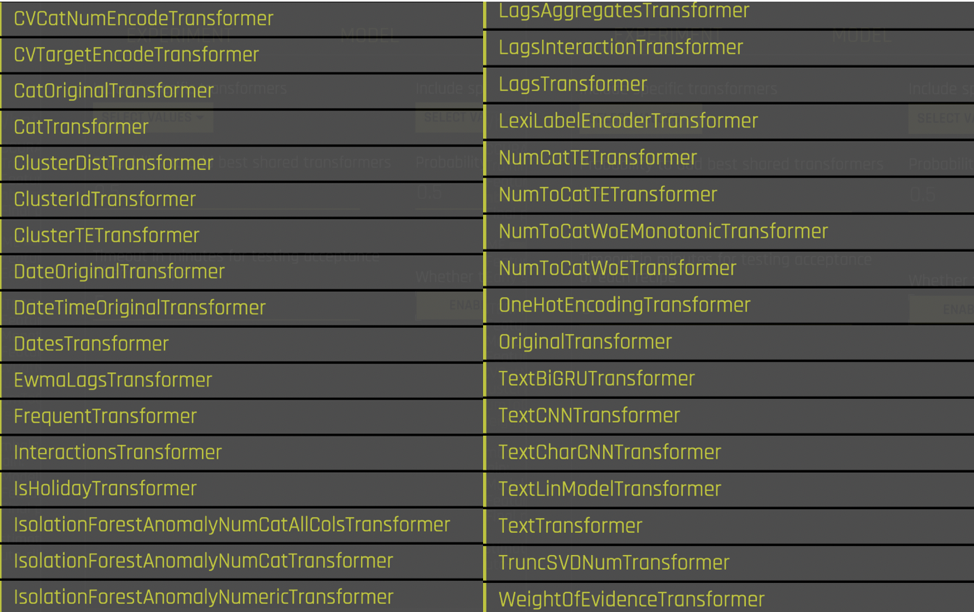
These transformers not only work on single columns but some of them can also take in multiple columns as inputs — when Driverless AI decides to invoke them as part of the evolutionary feature engineering process. This built-in list is a time-tested curated list that Kaggle Grandmasters of H2O baked in the product, so you as a data scientist don’t have to worry about iterating and writing code for it  to see what sticks in your model.
to see what sticks in your model.
What about built-in Algorithms and Scorers? Here you go:

Above is a list of leaderboard algorithms that work with tabular data even if the data is imbalanced! They consistently beat most classic algorithms and most of them are GPU enabled for performance.
What about the AI investment already made in creating IP over several years/months? How do I make sure I control the fate of the models in a way that I’m used to & of course, use all the convenience Driverless AI can offer?
For classification, for instance, can I run Naive Bayes, CatBoost, Support Vector Machines? How about Arima, Prophet, etc. for Time Series?
Of course, you can: Driverless AI supports adding multiple algorithms to the default mix, along with any feature engineering or scorers that your business is familiar with. Driverless AI would automatically create a pipeline of the winning algorithms, features, and scorer and create the “full” production pipeline automatically. Basically, you get to decide what default or custom goes into an Auto-ML tourney. The Automatic Documentation that gets generated will seamlessly integrate both default and custom choices and will be indistinguishable.
Make your own AI
Driverless AI offers a feature called Bring Your Own Recipe (BYOR). The community supported GitHub location gets updated often with feature/model/scorer code, that you can include in your AI/ML model.
If an algorithm or feature is not here, it’s fairly easy to inherit a similar code and make changes using the ‘how_to_write_a_recipe’ tutorials and slides in the GitHub location above. Adding a recipe to an experiment is as easy as going to Expert Settings and uploading the .py file from your Desktop or directly from the GitHub URL of the recipe. Once uploaded, it can be reused any number of times in the model.
Please read this great blog by Parul Pandey on step by step instructions to get BYOR going with your AI/ML models
How I customized my AI/ML Model using BYOR NLP recipes:
The default NLP transformers TextTE, TF/IDF, CharCNN_TE, TextCNN_TE, and BiGRU_TE works great with text data to extract features for the final predictive model. However, you can add more flavor to the feature engineering or even optionally only the NLP recipes below, to see if it makes a performance or accuracy difference.
Link to get above: https://github.com/h2oai/driverlessai-recipes/tree/master/transformers/nlp
I used Amazon Fine Food Reviews data to try the BYOR feature and got a few recipes installed like the text_meta_transformers, text_topic_modeling_tranformer, vader_text_sentiment_transformer , etc.. Some of these python files have multiple feature transformers inside. I uploaded the python files and checked them in the RECIPES tab in Expert Settings and using the Include Specific Transformers dropdown. See the list of transformers I picked:
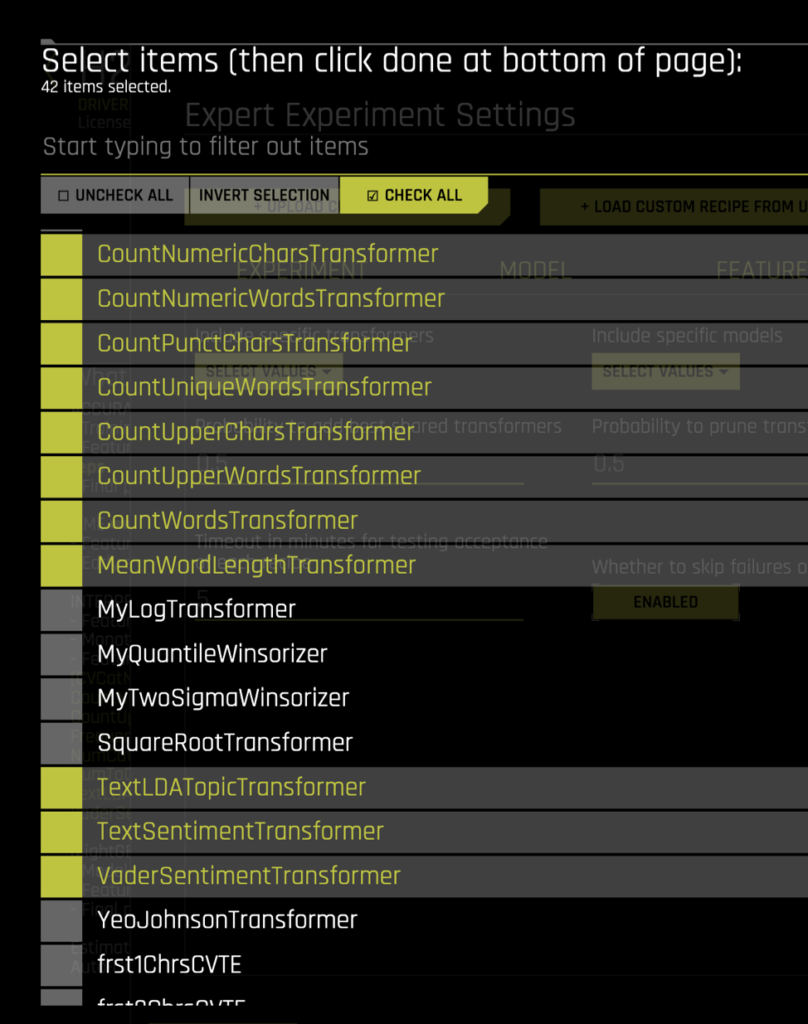
The names of the transformers should give away the feature it’s generating. So what’s the impact of these features on the final model? Check out the feature importance list for the final model:
At 0.9895 AUCPR , only using the text columns The BYOR features are showing up in the top N features in addition to the leaderboard TextBiGRU, TextCNN (Word2Vec ) and TextTargetEncoding transformations — using both the Summary and Description text fields!
How about using just the BYOR Recipes?
I turned off CNN/BiGRU and other internal Driverless AI Text Transformers. In this case, the data was easy enough that the BYOR features that use VaderSentiment, TextBlob and LDA python libraries + a mix of some basic Driverless AI recipes created a slightly less 0.9803 AUCPR model in less than 1/2 the time!
Why ‘Make your own AI’ is so cool?
Most businesses that have already months or years of investment in Data Scientists and Tools & Domain knowledge can reuse already discovered features and add them to the Driverless AI model in the form of recipes.
If the feature is useful and performs better than built-in ones, it would automatically be used by Driverless AI, along with other features to either increase performance, accuracy or both. The IP already created by businesses can now be internally reused in complex models that go into production. Data Scientists/Business folks basically can optionally turn on/off the built-in features & algorithms, as they see fit and take full control of the AI/ML pipeline.







