







Last updated: 08/26/19
Whether it’s healthcare, manufacturing or anything that we depend on either personal or in business, Prevention of a problem is always known to be better than cure!
Classic prevention techniques involve time-based checks to see how things are progressing, positively or negatively. Time-based checks are based on statistical measures like ‘how likely’ things would go wrong based on historical data. It works really well for the most part:
- Taking your vehicle to service on regular intervals (X miles or Ymonths) as recommended by your manufacturer, can reduce the odds of something failing unexpectedly.
- Doing yearly physical checkups with your Doctor can prevent any developing adverse condition.
- <name your favorite use case>
The total cost of disruption in business continuity or personal health care, is generally orders more than what is paid for periodic checks!
Note, that for time-based maintenance, we might still be using sensor data, but just not in real-time.
IoT — How sensor data takes this to the next level:
As opposed to reviewing the health of equipment, business or personal data once in X days, hours, weeks or months, how about collecting sensor data continuously and then predict and recommended fixes? Just do it when we see warning signs ahead of time? This is another level of preventive maintenance and big cost savings.

IoT or Internet of Things — Sensor data is collected continuously and we use that to predict if something is going to fail ahead of time (as determined by the use case).
An example personal health care use case — how to prevent sudden heart attacks or strokes by detecting symptoms from sensor data from wearable devices.
Challenges with Failure Prediction:
In most cases, failures are rare but significant events. Data could also be multi-variate in nature. Just using plain BI alerts on individual variables, usually creates a lot of false positives and negatives. If rules were written by domain experts on multiple variables, they are hard to sustain over time to be effective. Scoring in real-time is another aspect. Explaining the model is even more important — Ok, this event is imminent and why the model thinks that way?
In data science terms, they pose the following common challenges to building good AI/ML models,
- Highly imbalanced data — like failures can be sometimes <0.1% of historical data
- Multivariate — can be a mix of time intervals, multiple categorical and numeric variables
- Latency to creative prescriptive actions
- Explainability of models
- Continuous Learning to update models w/o full training each time.
Hard-disk failure use case with Driverless AI
In this blog post, we will build a model using BackBlaze.com hard-disk sensor data to predict failures. This link has both raw data as well as stats from sensor data collected from Back Blaze Data Center.
I took the 2019 Q1, Q2 sensor data CSV files and prepared a training and test data set. The data has serial numbers, the model name of hard-disk (like Hitachi, Seagate, Western Digital, etc.,) along with S.M.A.R.T stats collected each day from each hard disk. There is also a ‘failure’ column that has 0s for the most part, except on the day the hard-disk failed where the value is marked as 1. I renamed the original columns to indicate the name of the SMART variable. Here’s the data structure of the data set (partially from a SQL View in postgres, which is what I used to cleanse and create training/test data set):

Model Training and Test Data Set
The training set is from Jan-Apr 2019 and a test data set from May-Jun 2019. Made sure that there is no serial # overlap between the two sets so that the data sets are bit independent.
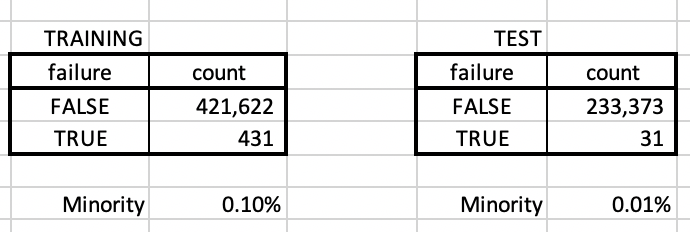
The # of rows that are marked failed in the training data set is 0.10% and in the test, it’s 0.01% — Highly skewed data set, for sure. The goal would be to use AI/ML learn from the TRAINING data set on what’s different about the rows that are marked failed=TRUE vs the one marked that’s marked failed=FALSE. Use that model to predict the TEST data set and see how close we come to predicting the 31 rows.
Cost of False Positives and Negatives …
When we do failure detection, we will get both false positives and negatives from the AI/ML model. False positives, in this case, means we are going to predict hard-disks as failed in the test set when in reality, they are not. We are also going to get False Negatives — we could be predicting hard-disks in the test data set as “not failed” when it actually failed.
As you can guess, false negatives are more expensive for failures that false positive. In a general case, the cost of replacing a lot of parts or components that “might” fail in the future is most likely cheaper than “not finding” the 2 potential failures, that can impact the business. On the health care use case, having people come to the doctor for getting a checkup and finding most of them ok (false positives), is infinitely better than lives lost because of 1 or more ‘false negatives’.
Caveat: Hard-disks in data centers are probably configured in RAID mode (fail-over) for servers, so it may be really ok. Above explanation is only valid, for situations without automatic failover.
Next Steps
Let’s find out in Part 2 of the blog post, how to setup H2O.ai’s Driverless AI for building preventive failure models both as row independent binary classification and time-series classification. Driverless AI uses Automatic Feature Engineering & Automatic Machine Learning to find signals in data to build AI/ML models. We will also do some explainability to figure what variables are more indicative of an imminent failure and partial dependence of each.







