What does it take to win a Kaggle competition? Let's hear it from the winner himself.
In this series of interviews, I present the stories of established Data Scientists and Kaggle Grandmasters at H2O.ai, who share their journey, inspirations, and accomplishments. These interviews are intended to motivate and encourage others who want to understand what it takes to be a Kaggle Grandmaster.
In this interview, I shall be sharing my interaction with Dmitry Gordeev, also known as dott in Kaggle world. He is a Kaggle Competition’s Grandmaster and a Senior Data Scientist at H2O.ai . Dmitry studied at Moscow State University and graduated as a specialist in applied math/data mining. Before H2O, he worked at UNIQA Insurance Group in Vienna, where his work revolved around credit risk management.
Dmitry and his team recently won the Indoor Location & Navigation competition on Kaggle with a considerable margin compared to the other teams. With this win, Dmitry now ranks 5th in the Kaggle competitions tier globally. Interestingly, Dmitry and Philipp Singer , The current No 1 (as of today) on Kaggle and a fellow Data Scientist at H2O.ai, have teamed up and won gold medals in numerous Kaggle competitions in the past. The duo participated under the team handle — The Zoo, which became synonymous with winning and regularly topping the Kaggle leaderboard. One of the landmark achievements of The Zoo was winning the NFL’s second annual Big Data Bowl . Theirs was the winning entry among 2,038 submissions on Kaggle for a top prize of $50,000.

The NFL director of data analytics, Mike Lopez, found their approach very thoughtful and even remarked: “To have an algorithm that’s able to generalize from historical data to plays they haven’t seen before is a hard thing to do.”
In this interview, we shall know more about Dmitry’s recent Kaggle win, his passion for Kaggle, and his work as a Data Scientist. Here is an excerpt from my conversation with Philipp:
Congratulations on winning the recently held “Indoor Location & Navigation” competition on Kaggle. Could you share with us your approach and your learnings from the competition?
Dmitry: It was quite an exciting competition for me, mainly because it touches on a new topic and a new type of data that I’ve never worked on before. In a nutshell, the competition is dedicated to improving phone navigation in shopping malls. GPS generally solves such tasks very well but only outdoors since it requires outdoor exposure for the best accuracy. However, it cannot adequately help you inside a multi-story shopping center. In this competition, Microsoft research encouraged us to utilize the data that a user permits their mobile phone to collect, to help identify where a person is and which path a person took. The data included recordings of wifi signals and their strength, which is helpful to identify the position, and sensor data stream to reconstruct the trajectory of movement over time.
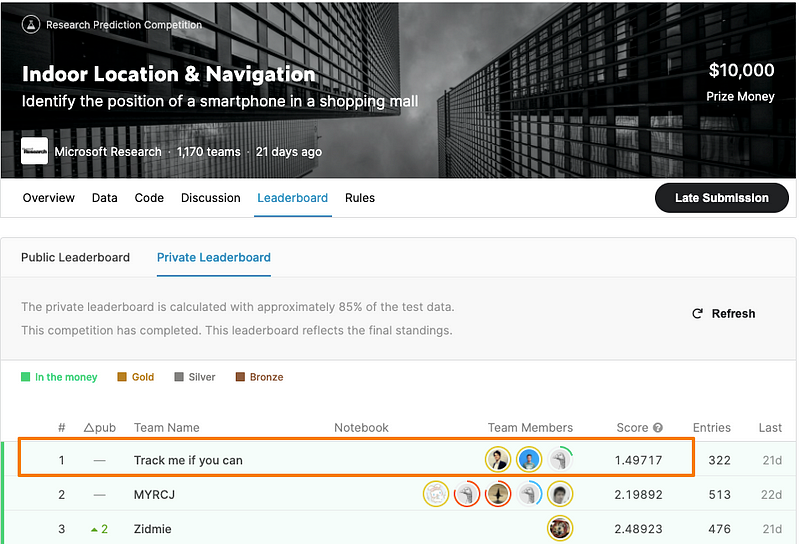
We managed to finish this competition at the top and beat all our competitors by a significant margin. Our predictions were 30%+ more accurate than the 2nd place team.
First of all, I need to mention my incredible teammates. The success in the competition was only possible due to an outstanding team effort. The competition required the amount of work that is barely possible for a single person to deliver. Compared to a typical Kaggle competition, the solution is very complex, as it consists of multiple steps, each requiring tailored data science approaches. I’ll summarize it briefly here, but we have also described it in detail and open-sourced the entire code on GitHub.
We split the problem into multiple blocks. The core ones include:
- predicting the location based on the wifi signal records (where we relied mainly on KNN and GBM classifiers),
- reconstructing the trajectory based on sensor data (with a family of CNN and RNN models), and
- an optimization routine to combine the outcome of the two.
The key feature of our solution, which helped us gain such a significant boost in accuracy, is the discrete optimization. Due to the peculiarities of the data collection, the points of predictions formed a discrete grid, which we relied upon with a modified beam search optimization algorithm. Our solution also relied on a highly complicated routine that injected additional grid points to cover the new areas of the shopping malls that didn’t appear in the training dataset.
You have been consistently doing well in Kaggle competitions. How did your tryst with Kaggle begin, and what keeps you motivated to compete again and again? kaggle
Dmitry: It was approximately 7–8 years ago when I found Kaggle as a platform to compete, but most importantly, to learn more about machine learning. The first competitions I tried gave me a great experience. It was the first time I fitted a Random Forest model on actual data and the very first time I discovered the importance of proper cross-validation . It was a steep learning curve, but I managed to get a bronze, silver, and even a gold medal in the very first three competitions. However, it was very time-consuming and required long hours of work. It became clear I couldn’t continue for long in such a rhythm, so I decided to take a break from Kaggle.
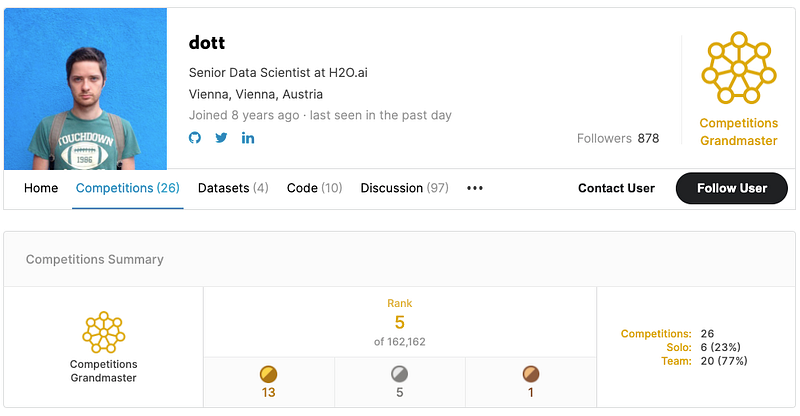
The second time I started competing actively on Kaggle was around two and a half years ago, teaming up with my colleague Philipp Singer.
“Having a reliable and passionate teammate was the key to success. Sharing the ideas, having multiple people coding and trying them out, ability to split work was absolutely crucial. But, above all, it is a team spirit that motivates you to try again and again after so many ideas fail; that is what helped us get to the top over and over.”
Could you tell us a bit about your background? Why did you opt for Data Science as a career?
Dmitry: I have a background in data mining from a Moscow State University, which corresponds to a master’s degree, but my career focused on credit risk management for quite some time. Kaggle, however, helped me to get back into the general Data Science area. Competing and learning helped me change my career path, and I’m extremely happy and grateful for that. It took me years to make this change, and those years included a lot of late-night studying, reading, and coding. They were anything but easy, but they were worth it.
You participated in the weekly COVID19 Global Forecasting challenge also where you performed very well. What insights were you able to gain from it?

Dmitry: COVID-19 Global Forecasting challenge was a way for my teammates and me to apply our skills and knowledge to something valuable when the pandemic started. We spent all our free time figuring out an approach that could give reliable predictions of the disease spread. But we were facing a problem, for which there was simply no data available, which could be reliably translated to what the world was going through. Our models managed to score high on the leaderboard in this series of competitions, but the accuracy of the results was way below what I was hoping for.
Any favorite ML resources(MOOCS, Blogs, etc..) you would like to share with the community? Community
Dmitry: It is tough to stay up to date with data science developments nowadays, not to mention the growing number of topics to follow. The progress in areas like NLP, Computer Vision, Reinforcement Learning, Explainability, etc., over the past few years, has been remarkable. To keep track of the latest developments, it is helpful to have multiple reliable sources of information about the research papers, new open-source repositories, competitions, and solutions. Kaggle is definitely an important one, as it is a great place to learn which methods work well for certain problems and which fail. It is also fruitful to follow your favorite people and companies on Twitter and other social media channels, read the H2O.ai blog, and other popular ones.
I am trying to keep up with as many Data Science topics as possible, as they frequently are connected in ways you might not expect. My favorite example is NLP methods, which work exceptionally well in chemistry and sports analytics tasks, though no texts are involved.
As a Data Scientist at H2O.ai, what are your roles, and in which specific areas do you work?
Dmitry: In my day-to-day work, I help our customers find the best solutions for their Data Science problems or the problems which haven’t been solved using data yet. These are the customers from various industries, such as finance, healthcare, retail sales, production, etc. Even though the use cases seem not related at first glance, the best ways to solve them frequently rely on the same Data Science approaches.

Apart from that, we are continuously looking for breakthrough ideas and working on bringing them to life. Anything that can help us make a step forward, especially in social and healthcare areas, is a topic I dedicate my efforts to. We are working together with multiple partners to bring Data Science models and approaches to help improve medical care. We tried to make a small contribution with our COVID-19 forecast models and their accuracy assessment. Needless to say, these activities are not only focused on models themselves but also on ways to make them reliable, robust, explainable, and hence trustworthy in helping make critical decisions.
What are some of the best things you have learned via Kaggle that you apply in your professional work at H2O.ai?
Dmitry: Nobody knows what the best way to solve a problem in the beginning is. Not even halfway through. It is an iterative process of testing, failing, learning from the failure, and repeating.
“The common approaches and state-of-the-art models usually suffice to achieve impressive results. But if you want to do better, you have to think outside the box. And it is a field with endless opportunities to be creative.”

I think this idea is what I took from Kaggle, and I apply it to my professional work. For many Data Science problems, there is already a well-developed approach or a state-of-the-art model architecture known. We need to prepare the data we have, adjust the model if required, and tune it. All these steps barely require any thought process involved and hence should be automated. The state-of-the-art models fitted to your data should become a commodity. The actual work should begin from there and focus on getting a better solution, finding a new approach, and a brand new idea of how to solve the problem.
Explainable AI is becoming a necessity rather than a choice. How much impact do you think it will have on the current AI landscape? community
Dmitry: AI explainability and interpretability are the topics that have always been important and are drawing even more and more attention lately. I think they will always go hand in hand with all future developments in machine learning. People are trying to explain even the most complicated models to understand the flaws and the risks of relying on the model alone. And I think this will remain a key goal of explainable AI — in a transparent way to show how a model derives predictions under given circumstances. This helps to learn how a model works for cases of interest. It also helps put a model under scrutiny to search for specific cases when a model behaves unexpectedly due to lack or bias in training data or the model architecture and design. It will reveal flaws that can be used to attack a model if possible or cause the model to deteriorate drastically if the environment changes, which will inevitably happen. Such adversarial testing will become a standard part of an explainable AI toolkit that will always be applied to a model before making a final decision.
The Data Science domain is rapidly evolving. How do you manage to keep up with all the latest developments? community
Dmitry: Reading past Kaggle competition solutions is a must. Whenever I face a new problem, I check the recent competition in the same or similar areas, looking for the best approaches and the ideas that didn’t work. Forums, social media, blogs, and group chats are also great ways to keep up with research papers and announcements I might have missed otherwise. Last but not least, taking part in competitions. There is no better way to learn than to try things yourself.
A word of advice for the Data Science and Kaggle aspirants who have just started or wish to start their Data Science journey? community
Dmitry: Data Science is an extensive and constantly growing area, so it is hard to get bored. I think there are still plenty of breakthroughs to happen soon, so it will only keep getting better. What amazes me the most is the variety of topics to work on. You can look at NFL statistics today and analyze the structure of mRNA molecules next week!
“And for those who are starting their Kaggle journey. I envy you. Don’t get me wrong; my path involved a great deal of sweat and tears. And, to be honest, it didn’t get easier. But I cherish every single moment of my success in the past, and so will you. And take good care of your mental health. It is hard to overestimate how important it is. Sometimes you need to take a break and go for a walk.”
Takeaways
In this very insightful interview, Dmitry touched upon several vital aspects of his life. His story is of sheer passion, hard work, and patience. Right from approaching a machine learning problem to creating a solution, Dmitry emphasizes the need to be consistent and out-of-the-box thinking. He also discusses the need for more explainability in AI to inculcate trust in the models we create. His journey has been and continues to be inspiring, and we cannot wait to see what other milestones he covers in the days to come.