






Machine Learning Interpretability

Interpretability in H2O Driverless AI
Overview
H2O Driverless AI provides robust interpretability of machine learning models to explain modeling results with the Machine Learning Interpretability (MLI) capability. MLI enables a data scientist to employ different techniques and methodologies for interpreting and explaining the results of its models with four charts that are generated automatically including: K-LIME, Shapley, Variable Importance, Decision Tree, Partial Dependence and more.
Key Capabilities of Our Machine Learning Interpretability
- Shapley
- k-LIME
- Surrogate Decision Trees
- Partial Dependence Plot
- LOCO
- Disparate Impact Analysis
Local Shapley feature importance shows how each feature directly impacts each individual row’s prediction. Local Shapley values are accurate, consistent, and likely suitable for creating reason codes and adverse action codes and always add up to the model prediction. Global Shapley feature importance provides an overall view of the drivers of your model’s predictions. Global Shapley values are reported for original features and any feature the Driverless AI system creates on its own.
k-LIME automatically builds linear model approximations to regions of complex Driverless AI models’ learned response functions. These penalized GLM surrogates are trained to model the predictions of the Driverless AI model and can be used to generate reason codes and English language explanations of complex Driverless AI models
The local surrogate decision tree path shows how the logic of the model is applied to any given individual. The decision paths hows approximately how row values impact Driverless AI model predictions for that row by showing the row’s path through the decision tree surrogate flow chart. The global surrogate decision tree provides an overall flowchart of the Driverless AI model’s decision making processes based on the original features. The surrogate decision tree shows higher and more frequent features in the tree that are more important to the Driverless AI model than lower or less frequent variables.
Partial dependence shows the average Driverless AI model prediction and its standard deviation for different values of important original features. This helps you understand the average model behavior for the most important original features.
Local feature importance describes how the combination of the learned model rules or parameters and an individual row’s attributes affect a model’s prediction for that row while taking nonlinearity and interactions into effect. Local feature importance values reported here are based on a variant of the leave-one-covariate-out (LOCO) method (Lei et al, 2017).
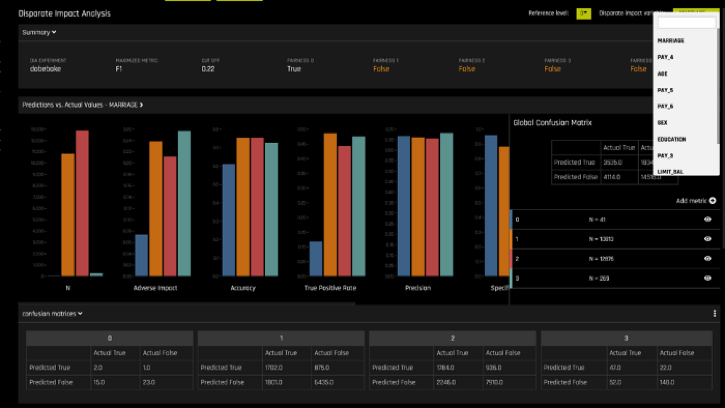
As part of the machine learning interpretability (MLI) capability in H2O Driverless AI, disparate impact analysis is used to test for sociological biases in models. This new feature allows users to analyze whether a model produces adverse outcomes for different demographic groups even if those features were not included in the original model. These checks are critical for regulated industries where demographic biases in the data can creep into models causing adverse effects on protected groups.
Resources
Watch Industry Experts Making Wave
Machine Learning Interpretability Tutorial
In this tutorial, you'll explore how to: launch an experiment, create an ML Interpretability report, explore explainability concepts such as Global Shapley, partial dependence plot, decision tree surrogate, K-LIME, Local Shapley, LOCO and individual conditional expectation.
In this tutorial, we will generate a machine learning model using an example financial dataset and explore some of the most popular ways to interpret a generated machine learning model. Furthermore, we will learn to interpret the results, graphs, scores and reason code values of H2O Driverless AI generated models.
